練習分類
列表
列表的尾部 列表的最後兩個元素 列表的第 N 個元素 列表的長度 反轉列表 回文 扁平化列表 消除重複項 打包連續重複項 執行長度編碼 修改的執行長度編碼 解碼執行長度編碼的列表 列表的執行長度編碼(直接解法) 複製列表的元素 將列表的元素重複指定次數 從列表中刪除每第 N 個元素 將列表分割成兩個部分;給定第一部分的長度 從列表中提取切片 將列表向左旋轉 N 個位置 從列表中移除第 K 個元素 在列表中給定位置插入元素 建立包含給定範圍內所有整數的列表 從列表中提取給定數量的隨機選取元素 樂透:從 1..M 的集合中抽出 N 個不同的隨機數字 產生列表中元素的隨機排列 從列表的 N 個元素中產生 K 個不同物件的組合 將集合的元素分組為不相交的子集 根據子列表的長度對列表的列表進行排序算術
判斷給定的整數是否為質數 判斷兩個正整數的最大公因數 判斷兩個正整數是否互質 計算歐拉函數 Φ(m) 判斷給定正整數的質因數 判斷給定正整數的質因數 (2) 計算歐拉函數 Φ(m) (改良版) 比較兩種計算歐拉函數的方法 質數列表 哥德巴赫猜想 哥德巴赫組合列表邏輯與編碼
邏輯表達式的真值表 (2 個變數) 邏輯表達式的真值表 格雷碼 霍夫曼編碼二元樹
建構完全平衡二元樹 對稱二元樹 二元搜尋樹 (字典) 產生與測試範式 建構高度平衡二元樹 建構具有給定節點數的高度平衡二元樹 計算二元樹的葉節點數量 將二元樹的葉節點收集到列表中 將二元樹的內部節點收集到列表中 將二元樹指定層級的節點收集到列表中 建構完整的二元樹 二元樹的佈局 (1) 二元樹的佈局 (2) 二元樹的佈局 (3) 二元樹的字串表示法 二元樹的前序和中序序列 二元樹的點字串表示法練習
本節的靈感來自 九十九個 Lisp 問題,而該問題又基於 Werner Hett 的「Prolog 問題列表」。針對每個問題,都會顯示一些簡單的測試——如果需要,它們也可以讓問題更清楚。要解決這些問題,我們建議您先安裝 OCaml 或在瀏覽器中使用它。以下問題的來源可在 GitHub 上取得。
每個練習都有一個難度等級,從初學者到進階。
列表的尾部
編寫一個函式 last : 'a list -> 'a option,該函式會傳回列表的最後一個元素
# last ["a" ; "b" ; "c" ; "d"];;
- : string option = Some "d"
# last [];;
- : 'a option = None
# let rec last = function
| [] -> None
| [ x ] -> Some x
| _ :: t -> last t;;
val last : 'a list -> 'a option = <fun>
列表的最後兩個元素
找出列表的最後兩個元素(最後一個和倒數第二個)。
# last_two ["a"; "b"; "c"; "d"];;
- : (string * string) option = Some ("c", "d")
# last_two ["a"];;
- : (string * string) option = None
# let rec last_two = function
| [] | [_] -> None
| [x; y] -> Some (x,y)
| _ :: t -> last_two t;;
val last_two : 'a list -> ('a * 'a) option = <fun>
列表的第 N 個元素
找出列表的第 N 個元素。
備註:OCaml 有 List.nth,它從 0 開始編號元素,如果索引超出範圍,則會引發例外狀況。
# List.nth ["a"; "b"; "c"; "d"; "e"] 2;;
- : string = "c"
# List.nth ["a"] 2;;
Exception: Failure "nth".
# let rec at k = function
| [] -> None
| h :: t -> if k = 0 then Some h else at (k - 1) t;;
val at : int -> 'a list -> 'a option = <fun>
列表的長度
找出列表的元素數。
OCaml 標準程式庫有 List.length,但我們要求您重新實作它。針對尾端遞迴解決方案,另有加分。
# length ["a"; "b"; "c"];;
- : int = 3
# length [];;
- : int = 0
此函式為尾端遞迴:無論列表大小為何,它都使用固定量的堆疊記憶體。
# let length list =
let rec aux n = function
| [] -> n
| _ :: t -> aux (n + 1) t
in
aux 0 list;;
val length : 'a list -> int = <fun>
反轉列表
反轉列表。
OCaml 標準程式庫有 List.rev,但我們要求您重新實作它。
# rev ["a"; "b"; "c"];;
- : string list = ["c"; "b"; "a"]
# let rev list =
let rec aux acc = function
| [] -> acc
| h :: t -> aux (h :: acc) t
in
aux [] list;;
val rev : 'a list -> 'a list = <fun>
迴文
找出列表是否為迴文。
提示:迴文是其自己的反轉。
# is_palindrome ["x"; "a"; "m"; "a"; "x"];;
- : bool = true
# not (is_palindrome ["a"; "b"]);;
- : bool = true
# let is_palindrome list =
(* One can use either the rev function from the previous problem, or the built-in List.rev *)
list = List.rev list;;
val is_palindrome : 'a list -> bool = <fun>
展平列表
展平巢狀列表結構。
type 'a node =
| One of 'a
| Many of 'a node list
# flatten [One "a"; Many [One "b"; Many [One "c" ;One "d"]; One "e"]];;
- : string list = ["a"; "b"; "c"; "d"; "e"]
# type 'a node =
| One of 'a
| Many of 'a node list;;
type 'a node = One of 'a | Many of 'a node list
# (* This function traverses the list, prepending any encountered elements
to an accumulator, which flattens the list in inverse order. It can
then be reversed to obtain the actual flattened list. *);;
# let flatten list =
let rec aux acc = function
| [] -> acc
| One x :: t -> aux (x :: acc) t
| Many l :: t -> aux (aux acc l) t
in
List.rev (aux [] list);;
val flatten : 'a node list -> 'a list = <fun>
消除重複項
消除列表元素中連續的重複項。
# compress ["a"; "a"; "a"; "a"; "b"; "c"; "c"; "a"; "a"; "d"; "e"; "e"; "e"; "e"];;
- : string list = ["a"; "b"; "c"; "a"; "d"; "e"]
# let rec compress = function
| a :: (b :: _ as t) -> if a = b then compress t else a :: compress t
| smaller -> smaller;;
val compress : 'a list -> 'a list = <fun>
封裝連續重複項
將列表元素中連續的重複項封裝到子列表中。
# pack ["a"; "a"; "a"; "a"; "b"; "c"; "c"; "a"; "a"; "d"; "d"; "e"; "e"; "e"; "e"];;
- : string list list =
[["a"; "a"; "a"; "a"]; ["b"]; ["c"; "c"]; ["a"; "a"]; ["d"; "d"];
["e"; "e"; "e"; "e"]]
# let pack list =
let rec aux current acc = function
| [] -> [] (* Can only be reached if original list is empty *)
| [x] -> (x :: current) :: acc
| a :: (b :: _ as t) ->
if a = b then aux (a :: current) acc t
else aux [] ((a :: current) :: acc) t in
List.rev (aux [] [] list);;
val pack : 'a list -> 'a list list = <fun>
執行長度編碼
如果您需要,請重新整理您對執行長度編碼的記憶。
這是一個範例
# encode ["a"; "a"; "a"; "a"; "b"; "c"; "c"; "a"; "a"; "d"; "e"; "e"; "e"; "e"];;
- : (int * string) list =
[(4, "a"); (1, "b"); (2, "c"); (2, "a"); (1, "d"); (4, "e")]
# let encode list =
let rec aux count acc = function
| [] -> [] (* Can only be reached if original list is empty *)
| [x] -> (count + 1, x) :: acc
| a :: (b :: _ as t) -> if a = b then aux (count + 1) acc t
else aux 0 ((count + 1, a) :: acc) t in
List.rev (aux 0 [] list);;
val encode : 'a list -> (int * 'a) list = <fun>
另一種解決方案,雖然較短但需要更多記憶體,是使用問題 9 中宣告的 pack 函式
# let pack list =
let rec aux current acc = function
| [] -> [] (* Can only be reached if original list is empty *)
| [x] -> (x :: current) :: acc
| a :: (b :: _ as t) ->
if a = b then aux (a :: current) acc t
else aux [] ((a :: current) :: acc) t in
List.rev (aux [] [] list);;
val pack : 'a list -> 'a list list = <fun>
# let encode list =
List.map (fun l -> (List.length l, List.hd l)) (pack list);;
val encode : 'a list -> (int * 'a) list = <fun>
修改的執行長度編碼
修改先前問題的結果,使得如果一個元素沒有重複項,則會直接複製到結果列表中。只有具有重複項的元素才會以 (N E) 列表的形式傳輸。
由於 OCaml 列表是同質的,因此需要定義一種型別來保存單一元素和子列表。
type 'a rle =
| One of 'a
| Many of int * 'a
# encode ["a"; "a"; "a"; "a"; "b"; "c"; "c"; "a"; "a"; "d"; "e"; "e"; "e"; "e"];;
- : string rle list =
[Many (4, "a"); One "b"; Many (2, "c"); Many (2, "a"); One "d";
Many (4, "e")]
# type 'a rle =
| One of 'a
| Many of int * 'a;;
type 'a rle = One of 'a | Many of int * 'a
# let encode l =
let create_tuple cnt elem =
if cnt = 1 then One elem
else Many (cnt, elem) in
let rec aux count acc = function
| [] -> []
| [x] -> (create_tuple (count + 1) x) :: acc
| hd :: (snd :: _ as tl) ->
if hd = snd then aux (count + 1) acc tl
else aux 0 ((create_tuple (count + 1) hd) :: acc) tl in
List.rev (aux 0 [] l);;
val encode : 'a list -> 'a rle list = <fun>
解碼執行長度編碼列表
給定一個如前一個問題中指定的執行長度編碼列表,建構其未壓縮的版本。
# decode [Many (4, "a"); One "b"; Many (2, "c"); Many (2, "a"); One "d"; Many (4, "e")];;
- : string list =
["a"; "a"; "a"; "a"; "b"; "c"; "c"; "a"; "a"; "d"; "e"; "e"; "e"; "e"]
# let decode list =
let rec many acc n x =
if n = 0 then acc else many (x :: acc) (n - 1) x
in
let rec aux acc = function
| [] -> acc
| One x :: t -> aux (x :: acc) t
| Many (n, x) :: t -> aux (many acc n x) t
in
aux [] (List.rev list);;
val decode : 'a rle list -> 'a list = <fun>
列表的執行長度編碼(直接解法)
直接實作所謂的執行長度編碼資料壓縮方法。也就是說,不要像在「將列表元素的連續重複項打包成子列表」問題中那樣明確建立包含重複項的子列表,而只是計算它們的數量。如同在「修改的執行長度編碼」問題中一樣,透過將單元素列表 (1 X) 替換為 X 來簡化結果列表。
# encode ["a";"a";"a";"a";"b";"c";"c";"a";"a";"d";"e";"e";"e";"e"];;
- : string rle list =
[Many (4, "a"); One "b"; Many (2, "c"); Many (2, "a"); One "d";
Many (4, "e")]
# let encode list =
let rle count x = if count = 0 then One x else Many (count + 1, x) in
let rec aux count acc = function
| [] -> [] (* Can only be reached if original list is empty *)
| [x] -> rle count x :: acc
| a :: (b :: _ as t) -> if a = b then aux (count + 1) acc t
else aux 0 (rle count a :: acc) t
in
List.rev (aux 0 [] list);;
val encode : 'a list -> 'a rle list = <fun>
複製列表中的元素
複製列表中的元素。
# duplicate ["a"; "b"; "c"; "c"; "d"];;
- : string list = ["a"; "a"; "b"; "b"; "c"; "c"; "c"; "c"; "d"; "d"]
# let rec duplicate = function
| [] -> []
| h :: t -> h :: h :: duplicate t;;
val duplicate : 'a list -> 'a list = <fun>
注意:此函數不是尾遞迴。您可以修改它使其成為尾遞迴嗎?
將列表中的元素複製指定的次數
將列表中的元素複製指定的次數。
# replicate ["a"; "b"; "c"] 3;;
- : string list = ["a"; "a"; "a"; "b"; "b"; "b"; "c"; "c"; "c"]
# let replicate list n =
let rec prepend n acc x =
if n = 0 then acc else prepend (n-1) (x :: acc) x in
let rec aux acc = function
| [] -> acc
| h :: t -> aux (prepend n acc h) t in
(* This could also be written as:
List.fold_left (prepend n) [] (List.rev list) *)
aux [] (List.rev list);;
val replicate : 'a list -> int -> 'a list = <fun>
請注意,之所以需要
List.rev list只是因為我們希望aux是 尾遞迴。
從列表中刪除每第 N 個元素
從列表中刪除每第 N 個元素。
# drop ["a"; "b"; "c"; "d"; "e"; "f"; "g"; "h"; "i"; "j"] 3;;
- : string list = ["a"; "b"; "d"; "e"; "g"; "h"; "j"]
# let drop list n =
let rec aux i = function
| [] -> []
| h :: t -> if i = n then aux 1 t else h :: aux (i + 1) t in
aux 1 list;;
val drop : 'a list -> int -> 'a list = <fun>
將列表分割成兩部分;第一部分的長度已給定
將列表分割成兩部分;第一部分的長度已給定。
如果第一部分的長度大於整個列表,則第一部分為列表本身,第二部分為空。
# split ["a"; "b"; "c"; "d"; "e"; "f"; "g"; "h"; "i"; "j"] 3;;
- : string list * string list =
(["a"; "b"; "c"], ["d"; "e"; "f"; "g"; "h"; "i"; "j"])
# split ["a"; "b"; "c"; "d"] 5;;
- : string list * string list = (["a"; "b"; "c"; "d"], [])
# let split list n =
let rec aux i acc = function
| [] -> List.rev acc, []
| h :: t as l -> if i = 0 then List.rev acc, l
else aux (i - 1) (h :: acc) t
in
aux n [] list;;
val split : 'a list -> int -> 'a list * 'a list = <fun>
從列表中擷取切片
給定兩個索引值 i 和 k,切片是指包含原始列表中第 i 個和第 k 個元素(包含兩個邊界)之間的元素的列表。從 0 開始計算元素(這是 List 模組編號元素的方式)。
# slice ["a"; "b"; "c"; "d"; "e"; "f"; "g"; "h"; "i"; "j"] 2 6;;
- : string list = ["c"; "d"; "e"; "f"; "g"]
# let slice list i k =
let rec take n = function
| [] -> []
| h :: t -> if n = 0 then [] else h :: take (n - 1) t
in
let rec drop n = function
| [] -> []
| h :: t as l -> if n = 0 then l else drop (n - 1) t
in
take (k - i + 1) (drop i list);;
val slice : 'a list -> int -> int -> 'a list = <fun>
此解決方案有一個缺點,即 take 函數不是 尾遞迴,因此在給定非常長的列表時可能會耗盡堆疊。您可能還會注意到 take 和 drop 的結構相似,您可能希望將它們的共同骨架抽象到一個單一函數中。以下是一個解決方案。
# let rec fold_until f acc n = function
| [] -> (acc, [])
| h :: t as l -> if n = 0 then (acc, l)
else fold_until f (f acc h) (n - 1) t
let slice list i k =
let _, list = fold_until (fun _ _ -> []) [] i list in
let taken, _ = fold_until (fun acc h -> h :: acc) [] (k - i + 1) list in
List.rev taken;;
val fold_until : ('a -> 'b -> 'a) -> 'a -> int -> 'b list -> 'a * 'b list =
<fun>
val slice : 'a list -> int -> int -> 'a list = <fun>
將列表向左旋轉 N 個位置
將列表向左旋轉 N 個位置。
# rotate ["a"; "b"; "c"; "d"; "e"; "f"; "g"; "h"] 3;;
- : string list = ["d"; "e"; "f"; "g"; "h"; "a"; "b"; "c"]
# let split list n =
let rec aux i acc = function
| [] -> List.rev acc, []
| h :: t as l -> if i = 0 then List.rev acc, l
else aux (i - 1) (h :: acc) t in
aux n [] list
let rotate list n =
let len = List.length list in
(* Compute a rotation value between 0 and len - 1 *)
let n = if len = 0 then 0 else (n mod len + len) mod len in
if n = 0 then list
else let a, b = split list n in b @ a;;
val split : 'a list -> int -> 'a list * 'a list = <fun>
val rotate : 'a list -> int -> 'a list = <fun>
從列表中移除第 K 個元素
從列表中移除第 K 個元素。
列表的第一個元素編號為 0,第二個為 1,依此類推...
# remove_at 1 ["a"; "b"; "c"; "d"];;
- : string list = ["a"; "c"; "d"]
# let rec remove_at n = function
| [] -> []
| h :: t -> if n = 0 then t else h :: remove_at (n - 1) t;;
val remove_at : int -> 'a list -> 'a list = <fun>
在列表的指定位置插入元素
從 0 開始計算列表元素。如果位置大於或等於列表的長度,則將元素插入到末尾。(如果位置為負數,則行為未指定。)
# insert_at "alfa" 1 ["a"; "b"; "c"; "d"];;
- : string list = ["a"; "alfa"; "b"; "c"; "d"]
# let rec insert_at x n = function
| [] -> [x]
| h :: t as l -> if n = 0 then x :: l else h :: insert_at x (n - 1) t;;
val insert_at : 'a -> int -> 'a list -> 'a list = <fun>
建立一個包含給定範圍內所有整數的列表
如果第一個參數大於第二個參數,則產生一個遞減順序的列表。
# range 4 9;;
- : int list = [4; 5; 6; 7; 8; 9]
# let range a b =
let rec aux a b =
if a > b then [] else a :: aux (a + 1) b
in
if a > b then List.rev (aux b a) else aux a b;;
val range : int -> int -> int list = <fun>
尾遞迴實作
# let range a b =
let rec aux acc high low =
if high >= low then
aux (high :: acc) (high - 1) low
else acc
in
if a < b then aux [] b a else List.rev (aux [] a b);;
val range : int -> int -> int list = <fun>
從列表中擷取指定數量的隨機選取元素
選取的項目應以列表形式傳回。我們使用 Random 模組,並在函數開始時使用 Random.init 0 初始化它以確保可重現性並驗證解決方案。但是,為了使函數真正隨機,應該移除對 Random.init 0 的呼叫
# rand_select ["a"; "b"; "c"; "d"; "e"; "f"; "g"; "h"] 3;;
- : string list = ["e"; "c"; "g"]
# let rand_select list n =
Random.init 0;
let rec extract acc n = function
| [] -> raise Not_found
| h :: t -> if n = 0 then (h, acc @ t) else extract (h :: acc) (n - 1) t
in
let extract_rand list len =
extract [] (Random.int len) list
in
let rec aux n acc list len =
if n = 0 then acc else
let picked, rest = extract_rand list len in
aux (n - 1) (picked :: acc) rest (len - 1)
in
let len = List.length list in
aux (min n len) [] list len;;
val rand_select : 'a list -> int -> 'a list = <fun>
樂透:從集合 1..M 中抽取 N 個不同的隨機數字
從集合 1..M 中抽取 N 個不同的隨機數字。
選取的數字應以列表形式傳回。
# lotto_select 6 49;;
- : int list = [20; 28; 45; 16; 24; 38]
# (* [range] and [rand_select] defined in problems above *)
let lotto_select n m = rand_select (range 1 m) n;;
val lotto_select : int -> int -> int list = <fun>
產生列表中元素的隨機排列
產生列表中元素的隨機排列。
# permutation ["a"; "b"; "c"; "d"; "e"; "f"];;
- : string list = ["c"; "d"; "f"; "e"; "b"; "a"]
# let permutation list =
let rec extract acc n = function
| [] -> raise Not_found
| h :: t -> if n = 0 then (h, acc @ t) else extract (h :: acc) (n - 1) t
in
let extract_rand list len =
extract [] (Random.int len) list
in
let rec aux acc list len =
if len = 0 then acc else
let picked, rest = extract_rand list len in
aux (picked :: acc) rest (len - 1)
in
aux [] list (List.length list);;
val permutation : 'a list -> 'a list = <fun>
產生從列表的 N 個元素中選取 K 個不同物件的組合
產生從列表的 N 個元素中選取 K 個不同物件的組合。
從 12 人組成的團體中選出 3 人委員會的方式有多少種?我們都知道有 C(12,3) = 220 種可能性(C(N,K) 表示眾所周知的二項式係數)。對於純數學家來說,這個結果可能很棒。但我們希望真的在列表中產生所有可能性。
# extract 2 ["a"; "b"; "c"; "d"];;
- : string list list =
[["a"; "b"]; ["a"; "c"]; ["a"; "d"]; ["b"; "c"]; ["b"; "d"]; ["c"; "d"]]
# let rec extract k list =
if k <= 0 then [[]]
else match list with
| [] -> []
| h :: tl ->
let with_h = List.map (fun l -> h :: l) (extract (k - 1) tl) in
let without_h = extract k tl in
with_h @ without_h;;
val extract : int -> 'a list -> 'a list list = <fun>
將集合的元素分組為不相交的子集
將集合的元素分組為不相交的子集
- 9 人團體可以有多少種方式分成 2 人、3 人和 4 人這 3 個不相交的小組?編寫一個函數,產生所有可能性並以列表形式傳回它們。
- 將上面的函數一般化,我們可以指定一個群組大小列表,並且該函數將傳回一個群組列表。
# group ["a"; "b"; "c"; "d"] [2; 1];;
- : string list list list =
[[["a"; "b"]; ["c"]]; [["a"; "c"]; ["b"]]; [["b"; "c"]; ["a"]];
[["a"; "b"]; ["d"]]; [["a"; "c"]; ["d"]]; [["b"; "c"]; ["d"]];
[["a"; "d"]; ["b"]]; [["b"; "d"]; ["a"]]; [["a"; "d"]; ["c"]];
[["b"; "d"]; ["c"]]; [["c"; "d"]; ["a"]]; [["c"; "d"]; ["b"]]]
# (* This implementation is less streamlined than the one-extraction
version, because more work is done on the lists after each
transform to prepend the actual items. The end result is cleaner
in terms of code, though. *)
let group list sizes =
let initial = List.map (fun size -> size, []) sizes in
(* The core of the function. Prepend accepts a list of groups,
each with the number of items that should be added, and
prepends the item to every group that can support it, thus
turning [1,a ; 2,b ; 0,c] into [ [0,x::a ; 2,b ; 0,c ];
[1,a ; 1,x::b ; 0,c]; [ 1,a ; 2,b ; 0,c ]]
Again, in the prolog language (for which these questions are
originally intended), this function is a whole lot simpler. *)
let prepend p list =
let emit l acc = l :: acc in
let rec aux emit acc = function
| [] -> emit [] acc
| (n, l) as h :: t ->
let acc = if n > 0 then emit ((n - 1, p :: l) :: t) acc
else acc in
aux (fun l acc -> emit (h :: l) acc) acc t
in
aux emit [] list
in
let rec aux = function
| [] -> [initial]
| h :: t -> List.concat_map (prepend h) (aux t)
in
let all = aux list in
(* Don't forget to eliminate all group sets that have non-full
groups *)
let complete = List.filter (List.for_all (fun (x, _) -> x = 0)) all in
List.map (List.map snd) complete;;
val group : 'a list -> int list -> 'a list list list = <fun>
根據子列表的長度對列表列表進行排序
根據子列表的長度對列表列表進行排序。
-
我們假設一個列表包含本身是列表的元素。目的是根據它們的長度對此列表的元素進行排序。例如,短列表優先,較長的列表稍後,反之亦然。
-
再次,我們假設一個列表包含本身是列表的元素。但這次的目的是根據它們的長度頻率對此列表的元素進行排序;也就是說,在預設情況下,排序是遞增完成的,長度罕見的列表會先放置,而長度較為頻繁的列表則會稍後放置。
# length_sort [["a"; "b"; "c"]; ["d"; "e"]; ["f"; "g"; "h"]; ["d"; "e"];
["i"; "j"; "k"; "l"]; ["m"; "n"]; ["o"]];;
- : string list list =
[["o"]; ["d"; "e"]; ["d"; "e"]; ["m"; "n"]; ["a"; "b"; "c"]; ["f"; "g"; "h"];
["i"; "j"; "k"; "l"]]
# frequency_sort [["a"; "b"; "c"]; ["d"; "e"]; ["f"; "g"; "h"]; ["d"; "e"];
["i"; "j"; "k"; "l"]; ["m"; "n"]; ["o"]];;
- : string list list =
[["i"; "j"; "k"; "l"]; ["o"]; ["a"; "b"; "c"]; ["f"; "g"; "h"]; ["d"; "e"];
["d"; "e"]; ["m"; "n"]]
(* We might not be allowed to use built-in List.sort, so here's an
eight-line implementation of insertion sort — O(n²) time
complexity. *)
let rec insert cmp e = function
| [] -> [e]
| h :: t as l -> if cmp e h <= 0 then e :: l else h :: insert cmp e t
let rec sort cmp = function
| [] -> []
| h :: t -> insert cmp h (sort cmp t)
(* Sorting according to length : prepend length, sort, remove length *)
let length_sort lists =
let lists = List.map (fun list -> List.length list, list) lists in
let lists = sort (fun a b -> compare (fst a) (fst b)) lists in
List.map snd lists
;;
(* Sorting according to length frequency : prepend frequency, sort,
remove frequency. Frequencies are extracted by sorting lengths
and applying RLE to count occurrences of each length (see problem
"Run-length encoding of a list.") *)
let rle list =
let rec aux count acc = function
| [] -> [] (* Can only be reached if original list is empty *)
| [x] -> (x, count + 1) :: acc
| a :: (b :: _ as t) ->
if a = b then aux (count + 1) acc t
else aux 0 ((a, count + 1) :: acc) t in
aux 0 [] list
let frequency_sort lists =
let lengths = List.map List.length lists in
let freq = rle (sort compare lengths) in
let by_freq =
List.map (fun list -> List.assoc (List.length list) freq , list) lists in
let sorted = sort (fun a b -> compare (fst a) (fst b)) by_freq in
List.map snd sorted
判斷給定的整數是否為質數
判斷給定的整數是否為質數。
# not (is_prime 1);;
- : bool = true
# is_prime 7;;
- : bool = true
# not (is_prime 12);;
- : bool = true
回想一下,當且僅當 n mod d = 0 時,d 才會整除 n。這是一個簡單的解法。請參閱 埃拉托斯特尼篩法以獲得更聰明的解法。
# let is_prime n =
let n = abs n in
let rec is_not_divisor d =
d * d > n || (n mod d <> 0 && is_not_divisor (d + 1)) in
n > 1 && is_not_divisor 2;;
val is_prime : int -> bool = <fun>
判斷兩個正整數的最大公因數
判斷兩個正整數的最大公因數。
使用歐幾里得算法。
# gcd 13 27;;
- : int = 1
# gcd 20536 7826;;
- : int = 2
# let rec gcd a b =
if b = 0 then a else gcd b (a mod b);;
val gcd : int -> int -> int = <fun>
判斷兩個正整數是否互質
判斷兩個正整數是否互質。
如果兩個數的最大公因數等於 1,則它們互質。
# coprime 13 27;;
- : bool = true
# not (coprime 20536 7826);;
- : bool = true
# (* [gcd] is defined in the previous question *)
let coprime a b = gcd a b = 1;;
val coprime : int -> int -> bool = <fun>
計算歐拉總計函數 Φ(m)
歐拉的所謂總計函數 φ(m) 定義為與 m 互質的正整數 r (1 ≤ r < m) 的數量。我們令 φ(1) = 1。
找出如果 m 是質數,φ(m) 的值是多少。歐拉總計函數在最廣泛使用的公鑰密碼方法之一 (RSA) 中扮演著重要角色。在這個練習中,您應該使用最基本的方法來計算這個函數(我們稍後將討論更聰明的方法)。
# phi 10;;
- : int = 4
# (* [coprime] is defined in the previous question *)
let phi n =
let rec count_coprime acc d =
if d < n then
count_coprime (if coprime n d then acc + 1 else acc) (d + 1)
else acc
in
if n = 1 then 1 else count_coprime 0 1;;
val phi : int -> int = <fun>
判斷給定正整數的質因數
建構一個包含升冪質因數的扁平列表。
# factors 315;;
- : int list = [3; 3; 5; 7]
# (* Recall that d divides n iff [n mod d = 0] *)
let factors n =
let rec aux d n =
if n = 1 then [] else
if n mod d = 0 then d :: aux d (n / d) else aux (d + 1) n
in
aux 2 n;;
val factors : int -> int list = <fun>
判斷給定正整數的質因數 (2)
建構一個包含質因數及其多重性的列表。
提示:這個問題與問題 列表的執行長度編碼(直接解法)類似。
# factors 315;;
- : (int * int) list = [(3, 2); (5, 1); (7, 1)]
# let factors n =
let rec aux d n =
if n = 1 then [] else
if n mod d = 0 then
match aux d (n / d) with
| (h, n) :: t when h = d -> (h, n + 1) :: t
| l -> (d, 1) :: l
else aux (d + 1) n
in
aux 2 n;;
val factors : int -> (int * int) list = <fun>
計算歐拉總計函數 Φ(m)(已改進)
請參閱問題「計算歐拉總計函數 φ(m)」以了解歐拉總計函數的定義。如果已知一個數字 m 的質因數列表,其形式如上一個問題,則可以按如下方式有效計算函數 phi(m):令 [(p1, m1); (p2, m2); (p3, m3); ...] 是給定數字 m 的質因數(及其多重性)列表。然後可以使用以下公式計算 φ(m)
φ(m) = (p1 - 1) × p1m1 - 1 × (p2 - 1) × p2m2 - 1 × (p3 - 1) × p3m3 - 1 × ⋯
# phi_improved 10;;
- : int = 4
# phi_improved 13;;
- : int = 12
(* Naive power function. *)
let rec pow n p = if p < 1 then 1 else n * pow n (p - 1)
(* [factors] is defined in the previous question. *)
let phi_improved n =
let rec aux acc = function
| [] -> acc
| (p, m) :: t -> aux ((p - 1) * pow p (m - 1) * acc) t
in
aux 1 (factors n)
比較兩種計算歐拉總計函數的方法
使用問題「計算歐拉總計函數 φ(m)」和「計算歐拉總計函數 φ(m) (已改進)」的解決方案來比較演算法。以邏輯推斷的數量作為效率的衡量標準。嘗試計算 φ(10090) 作為範例。
timeit phi 10090
# (* Naive [timeit] function. It requires the [Unix] module to be loaded. *)
let timeit f a =
let t0 = Unix.gettimeofday() in
ignore (f a);
let t1 = Unix.gettimeofday() in
t1 -. t0;;
val timeit : ('a -> 'b) -> 'a -> float = <fun>
質數列表
給定整數的範圍(由其下限和上限表示),建構該範圍內所有質數的列表。
# List.length (all_primes 2 7920);;
- : int = 1000
# let is_prime n =
let n = max n (-n) in
let rec is_not_divisor d =
d * d > n || (n mod d <> 0 && is_not_divisor (d + 1))
in
is_not_divisor 2
let rec all_primes a b =
if a > b then [] else
let rest = all_primes (a + 1) b in
if is_prime a then a :: rest else rest;;
val is_prime : int -> bool = <fun>
val all_primes : int -> int -> int list = <fun>
哥德巴赫猜想
哥德巴赫猜想表示,每個大於 2 的正偶數都是兩個質數的和。範例:28 = 5 + 23。這是數論中最著名的事實之一,尚未證明其在一般情況下是正確的。它已經被數值確認到非常大的數字。編寫一個函數來找出加總為給定偶數的兩個質數。
# goldbach 28;;
- : int * int = (5, 23)
# (* [is_prime] is defined in the previous solution *)
let goldbach n =
let rec aux d =
if is_prime d && is_prime (n - d) then (d, n - d)
else aux (d + 1)
in
aux 2;;
val goldbach : int -> int * int = <fun>
哥德巴赫組合列表
給定整數的範圍(由其下限和上限表示),列印所有偶數及其哥德巴赫組合的列表。
在大多數情況下,如果將一個偶數寫成兩個質數的和,其中一個質數會非常小。很少有質數都大於 50。試著找出在 2..3000 的範圍內有多少這種情況。
# goldbach_list 9 20;;
- : (int * (int * int)) list =
[(10, (3, 7)); (12, (5, 7)); (14, (3, 11)); (16, (3, 13)); (18, (5, 13));
(20, (3, 17))]
# (* [goldbach] is defined in the previous question. *)
let rec goldbach_list a b =
if a > b then [] else
if a mod 2 = 1 then goldbach_list (a + 1) b
else (a, goldbach a) :: goldbach_list (a + 2) b
let goldbach_limit a b lim =
List.filter (fun (_, (a, b)) -> a > lim && b > lim) (goldbach_list a b);;
val goldbach_list : int -> int -> (int * (int * int)) list = <fun>
val goldbach_limit : int -> int -> int -> (int * (int * int)) list = <fun>
邏輯表達式的真值表(2 個變數)
讓我們定義一種用於布林表達式的簡單「語言」,其中包含變數
# type bool_expr =
| Var of string
| Not of bool_expr
| And of bool_expr * bool_expr
| Or of bool_expr * bool_expr;;
type bool_expr =
Var of string
| Not of bool_expr
| And of bool_expr * bool_expr
| Or of bool_expr * bool_expr
然後可以用前綴表示法寫出兩個變數的邏輯表達式。例如,(a ∨ b) ∧ (a ∧ b) 寫成
# And (Or (Var "a", Var "b"), And (Var "a", Var "b"));;
- : bool_expr = And (Or (Var "a", Var "b"), And (Var "a", Var "b"))
定義一個函數 table2,該函數傳回給定邏輯表達式中兩個變數(指定為引數)的真值表。傳回值必須是包含 (value_of_a, value_of_b, value_of_expr) 的三元組列表。
# table2 "a" "b" (And (Var "a", Or (Var "a", Var "b")));;
- : (bool * bool * bool) list =
[(true, true, true); (true, false, true); (false, true, false);
(false, false, false)]
# let rec eval2 a val_a b val_b = function
| Var x -> if x = a then val_a
else if x = b then val_b
else failwith "The expression contains an invalid variable"
| Not e -> not (eval2 a val_a b val_b e)
| And(e1, e2) -> eval2 a val_a b val_b e1 && eval2 a val_a b val_b e2
| Or(e1, e2) -> eval2 a val_a b val_b e1 || eval2 a val_a b val_b e2
let table2 a b expr =
[(true, true, eval2 a true b true expr);
(true, false, eval2 a true b false expr);
(false, true, eval2 a false b true expr);
(false, false, eval2 a false b false expr)];;
val eval2 : string -> bool -> string -> bool -> bool_expr -> bool = <fun>
val table2 : string -> string -> bool_expr -> (bool * bool * bool) list =
<fun>
邏輯表達式的真值表
以這樣的方式一般化先前的問題:邏輯表達式可以包含任意數量的邏輯變數。以這樣的方式定義 table:table variables expr 會傳回表達式 expr 的真值表,其中包含 variables 中列舉的邏輯變數。
# table ["a"; "b"] (And (Var "a", Or (Var "a", Var "b")));;
- : ((string * bool) list * bool) list =
[([("a", true); ("b", true)], true); ([("a", true); ("b", false)], true);
([("a", false); ("b", true)], false); ([("a", false); ("b", false)], false)]
# (* [val_vars] is an associative list containing the truth value of
each variable. For efficiency, a Map or a Hashtlb should be
preferred. *)
let rec eval val_vars = function
| Var x -> List.assoc x val_vars
| Not e -> not (eval val_vars e)
| And(e1, e2) -> eval val_vars e1 && eval val_vars e2
| Or(e1, e2) -> eval val_vars e1 || eval val_vars e2
(* Again, this is an easy and short implementation rather than an
efficient one. *)
let rec table_make val_vars vars expr =
match vars with
| [] -> [(List.rev val_vars, eval val_vars expr)]
| v :: tl ->
table_make ((v, true) :: val_vars) tl expr
@ table_make ((v, false) :: val_vars) tl expr
let table vars expr = table_make [] vars expr;;
val eval : (string * bool) list -> bool_expr -> bool = <fun>
val table_make :
(string * bool) list ->
string list -> bool_expr -> ((string * bool) list * bool) list = <fun>
val table : string list -> bool_expr -> ((string * bool) list * bool) list =
<fun>
格雷碼
n 位元格雷碼是根據特定規則建構的 n 位元字串序列。例如,
n = 1: C(1) = ['0', '1'].
n = 2: C(2) = ['00', '01', '11', '10'].
n = 3: C(3) = ['000', '001', '011', '010', '110', '111', '101', '100'].
找出建構規則並編寫具有以下規格的函數:gray n 傳回 n 位元格雷碼。
# gray 1;;
- : string list = ["0"; "1"]
# gray 2;;
- : string list = ["00"; "01"; "11"; "10"]
# gray 3;;
- : string list = ["000"; "001"; "011"; "010"; "110"; "111"; "101"; "100"]
# let gray n =
let rec gray_next_level k l =
if k < n then
(* This is the core part of the Gray code construction.
* first_half is reversed and has a "0" attached to every element.
* Second part is reversed (it must be reversed for correct gray code).
* Every element has "1" attached to the front.*)
let (first_half,second_half) =
List.fold_left (fun (acc1,acc2) x ->
(("0" ^ x) :: acc1, ("1" ^ x) :: acc2)) ([], []) l
in
(* List.rev_append turns first_half around and attaches it to second_half.
* The result is the modified first_half in correct order attached to
* the second_half modified in reversed order.*)
gray_next_level (k + 1) (List.rev_append first_half second_half)
else l
in
gray_next_level 1 ["0"; "1"];;
val gray : int -> string list = <fun>
霍夫曼碼
首先,請查閱一本關於離散數學或演算法的好書,以詳細了解霍夫曼碼(您可以從 維基百科頁面 開始)!
我們考慮一組具有各自頻率的符號。例如,如果字母為 "a",..., "f"(表示為位置 0,...5),且各自頻率為 45、13、12、16、9、5
# let fs = [("a", 45); ("b", 13); ("c", 12); ("d", 16);
("e", 9); ("f", 5)];;
val fs : (string * int) list =
[("a", 45); ("b", 13); ("c", 12); ("d", 16); ("e", 9); ("f", 5)]
我們的目標是為所有符號 s 建構霍夫曼碼 c 字。在我們的範例中,結果可能是 hs = [("a", "0"); ("b", "101"); ("c", "100"); ("d", "111"); ("e", "1101"); ("f", "1100")](或 hs = [("a", "1");...])。該任務應由定義如下的函數 huffman 來執行:huffman(fs) 傳回頻率表 fs 的霍夫曼碼表
# huffman fs;;
- : (string * string) list =
[("a", "0"); ("c", "100"); ("b", "101"); ("f", "1100"); ("e", "1101");
("d", "111")]
# (* Simple priority queue where the priorities are integers 0..100.
The node with the lowest probability comes first. *)
module Pq = struct
type 'a t = {data: 'a list array; mutable first: int}
let make() = {data = Array.make 101 []; first = 101}
let add q p x =
q.data.(p) <- x :: q.data.(p); q.first <- min p q.first
let get_min q =
if q.first = 101 then None else
match q.data.(q.first) with
| [] -> assert false
| x :: tl ->
let p = q.first in
q.data.(q.first) <- tl;
while q.first < 101 && q.data.(q.first) = [] do
q.first <- q.first + 1
done;
Some(p, x)
end
type tree =
| Leaf of string
| Node of tree * tree
let rec huffman_tree q =
match Pq.get_min q, Pq.get_min q with
| Some(p1, t1), Some(p2, t2) -> Pq.add q (p1 + p2) (Node(t1, t2));
huffman_tree q
| Some(_, t), None | None, Some(_, t) -> t
| None, None -> assert false
(* Build the prefix-free binary code from the tree *)
let rec prefixes_of_tree prefix = function
| Leaf s -> [(s, prefix)]
| Node(t0, t1) -> prefixes_of_tree (prefix ^ "0") t0
@ prefixes_of_tree (prefix ^ "1") t1
let huffman fs =
if List.fold_left (fun s (_, p) -> s + p) 0 fs <> 100 then
failwith "huffman: sum of weights must be 100";
let q = Pq.make () in
List.iter (fun (s, f) -> Pq.add q f (Leaf s)) fs;
prefixes_of_tree "" (huffman_tree q);;
module Pq :
sig
type 'a t = { data : 'a list array; mutable first : int; }
val make : unit -> 'a t
val add : 'a t -> int -> 'a -> unit
val get_min : 'a t -> (int * 'a) option
end
type tree = Leaf of string | Node of tree * tree
val huffman_tree : tree Pq.t -> tree = <fun>
val prefixes_of_tree : string -> tree -> (string * string) list = <fun>
val huffman : (string * int) list -> (string * string) list = <fun>
建構完全平衡的二元樹
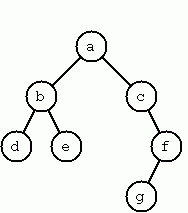
二元樹不是空的,就是由一個根元素和兩個後繼者組成,而後繼者本身也是二元樹。
在 OCaml 中,可以定義一個新的型別 binary_tree,它在每個節點攜帶型別為 'a 的任意值(因此是多型的)。
# type 'a binary_tree =
| Empty
| Node of 'a * 'a binary_tree * 'a binary_tree;;
type 'a binary_tree = Empty | Node of 'a * 'a binary_tree * 'a binary_tree
以下是攜帶 char 資料的樹範例
# let example_tree =
Node ('a', Node ('b', Node ('d', Empty, Empty), Node ('e', Empty, Empty)),
Node ('c', Empty, Node ('f', Node ('g', Empty, Empty), Empty)));;
val example_tree : char binary_tree =
Node ('a', Node ('b', Node ('d', Empty, Empty), Node ('e', Empty, Empty)),
Node ('c', Empty, Node ('f', Node ('g', Empty, Empty), Empty)))
在 OCaml 中,嚴格的型別規範保證,如果你取得一個 binary_tree 型別的值,那麼它一定是透過兩個建構子 Empty 和 Node 所建立的。
在一個完全平衡二元樹中,每個節點都符合以下特性:它的左子樹的節點數量和右子樹的節點數量幾乎相等,這表示它們的差異不超過一。
撰寫一個函式 cbal_tree,為給定的節點數量建構完全平衡二元樹。這個函式應該透過回溯法產生所有解。將字母 'x' 作為資訊放入樹的所有節點中。
# cbal_tree 4;;
- : char binary_tree/2 list =
[Node ('x', Node ('x', Empty, Empty),
Node ('x', Node ('x', Empty, Empty), Empty));
Node ('x', Node ('x', Empty, Empty),
Node ('x', Empty, Node ('x', Empty, Empty)));
Node ('x', Node ('x', Node ('x', Empty, Empty), Empty),
Node ('x', Empty, Empty));
Node ('x', Node ('x', Empty, Node ('x', Empty, Empty)),
Node ('x', Empty, Empty))]
# (* Build all trees with given [left] and [right] subtrees. *)
let add_trees_with left right all =
let add_right_tree all l =
List.fold_left (fun a r -> Node ('x', l, r) :: a) all right in
List.fold_left add_right_tree all left
let rec cbal_tree n =
if n = 0 then [Empty]
else if n mod 2 = 1 then
let t = cbal_tree (n / 2) in
add_trees_with t t []
else (* n even: n-1 nodes for the left & right subtrees altogether. *)
let t1 = cbal_tree (n / 2 - 1) in
let t2 = cbal_tree (n / 2) in
add_trees_with t1 t2 (add_trees_with t2 t1 []);;
val add_trees_with :
char binary_tree list ->
char binary_tree list -> char binary_tree list -> char binary_tree list =
<fun>
val cbal_tree : int -> char binary_tree list = <fun>
對稱二元樹
如果可以通過根節點畫一條垂直線,並且右子樹是左子樹的鏡像,我們就稱二元樹是對稱的。撰寫一個函式 is_symmetric 來檢查給定的二元樹是否對稱。
提示: 先撰寫一個函式 is_mirror 來檢查一個樹是否是另一個樹的鏡像。我們只關心結構,不關心節點的內容。
# let rec is_mirror t1 t2 =
match t1, t2 with
| Empty, Empty -> true
| Node(_, l1, r1), Node(_, l2, r2) ->
is_mirror l1 r2 && is_mirror r1 l2
| _ -> false
let is_symmetric = function
| Empty -> true
| Node(_, l, r) -> is_mirror l r;;
val is_mirror : 'a binary_tree -> 'b binary_tree -> bool = <fun>
val is_symmetric : 'a binary_tree -> bool = <fun>
二元搜尋樹(字典)
從一個整數列表建構一個二元搜尋樹。
# construct [3; 2; 5; 7; 1];;
- : int binary_tree =
Node (3, Node (2, Node (1, Empty, Empty), Empty),
Node (5, Empty, Node (7, Empty, Empty)))
然後使用這個函式來測試前一個問題的解答。
# is_symmetric (construct [5; 3; 18; 1; 4; 12; 21]);;
- : bool = true
# not (is_symmetric (construct [3; 2; 5; 7; 4]));;
- : bool = true
# let rec insert tree x = match tree with
| Empty -> Node (x, Empty, Empty)
| Node (y, l, r) ->
if x = y then tree
else if x < y then Node (y, insert l x, r)
else Node (y, l, insert r x)
let construct l = List.fold_left insert Empty l;;
val insert : 'a binary_tree -> 'a -> 'a binary_tree = <fun>
val construct : 'a list -> 'a binary_tree = <fun>
產生與測試範式
應用產生與測試範式來建構所有具有給定節點數量的對稱、完全平衡二元樹。
# sym_cbal_trees 5;;
- : char binary_tree list =
[Node ('x', Node ('x', Node ('x', Empty, Empty), Empty),
Node ('x', Empty, Node ('x', Empty, Empty)));
Node ('x', Node ('x', Empty, Node ('x', Empty, Empty)),
Node ('x', Node ('x', Empty, Empty), Empty))]
具有 57 個節點的這種樹有多少棵?研究一下給定節點數量時有多少解?如果節點數量是偶數呢?撰寫一個適當的函式。
# List.length (sym_cbal_trees 57);;
- : int = 256
# let sym_cbal_trees n =
List.filter is_symmetric (cbal_tree n);;
val sym_cbal_trees : int -> char binary_tree list = <fun>
建構高度平衡二元樹
在一個高度平衡二元樹中,每個節點都符合以下特性:它的左子樹的高度和右子樹的高度幾乎相等,這表示它們的差異不超過一。
撰寫一個函式 hbal_tree,為給定的高度建構高度平衡二元樹。這個函式應該透過回溯法產生所有解。將字母 'x' 作為資訊放入樹的所有節點中。
# let t = hbal_tree 3;;
val t : char binary_tree list =
[Node ('x', Node ('x', Empty, Node ('x', Empty, Empty)),
Node ('x', Empty, Node ('x', Empty, Empty)));
Node ('x', Node ('x', Empty, Node ('x', Empty, Empty)),
Node ('x', Node ('x', Empty, Empty), Empty));
Node ('x', Node ('x', Empty, Node ('x', Empty, Empty)),
Node ('x', Node ('x', Empty, Empty), Node ('x', Empty, Empty)));
Node ('x', Node ('x', Node ('x', Empty, Empty), Empty),
Node ('x', Empty, Node ('x', Empty, Empty)));
Node ('x', Node ('x', Node ('x', Empty, Empty), Empty),
Node ('x', Node ('x', Empty, Empty), Empty));
Node ('x', Node ('x', Node ('x', Empty, Empty), Empty),
Node ('x', Node ('x', Empty, Empty), Node ('x', Empty, Empty)));
Node ('x', Node ('x', Node ('x', Empty, Empty), Node ('x', Empty, Empty)),
Node ('x', Empty, Node ('x', Empty, Empty)));
Node ('x', Node ('x', Node ('x', Empty, Empty), Node ('x', Empty, Empty)),
Node ('x', Node ('x', Empty, Empty), Empty));
Node ('x', Node ('x', Node ('x', Empty, Empty), Node ('x', Empty, Empty)),
Node ('x', Node ('x', Empty, Empty), Node ('x', Empty, Empty)));
Node ('x', Node ('x', Empty, Node ('x', Empty, Empty)),
Node ('x', Empty, Empty));
Node ('x', Node ('x', Node ('x', Empty, Empty), Empty),
Node ('x', Empty, Empty));
Node ('x', Node ('x', Node ('x', Empty, Empty), Node ('x', Empty, Empty)),
Node ('x', Empty, Empty));
Node ('x', Node ('x', Empty, Empty),
Node ('x', Empty, Node ('x', Empty, Empty)));
Node ('x', Node ('x', Empty, Empty),
Node ('x', Node ('x', Empty, Empty), Empty));
Node ('x', Node ('x', Empty, Empty),
Node ('x', Node ('x', Empty, Empty), Node ('x', Empty, Empty)))]
函式 add_trees_with 定義於建構完全平衡二元樹的解答中。
# let rec hbal_tree n =
if n = 0 then [Empty]
else if n = 1 then [Node ('x', Empty, Empty)]
else
(* [add_trees_with left right trees] is defined in a question above. *)
let t1 = hbal_tree (n - 1)
and t2 = hbal_tree (n - 2) in
add_trees_with t1 t1 (add_trees_with t1 t2 (add_trees_with t2 t1 []));;
val hbal_tree : int -> char binary_tree list = <fun>
建構具有給定節點數量的高度平衡二元樹
考慮一個高度為 h 的高度平衡二元樹。它最多可以包含多少個節點?顯然,max_nodes = 2h - 1。
# let max_nodes h = 1 lsl h - 1;;
val max_nodes : int -> int = <fun>
最少節點數
然而,最少節點數 min_nodes 是多少?這個問題比較困難。嘗試找出一個遞迴的陳述,並將其轉化為一個函式 min_nodes,定義如下:min_nodes h 會返回高度為 h 的高度平衡二元樹中的最少節點數。
最少高度
另一方面,我們可能會問:一個具有 N 個節點的高度平衡二元樹的最小(和最大)高度 H 是多少?min_height(和 max_height n)會返回具有 n 個節點的高度平衡二元樹的最小(和最大)高度。
建構樹
現在,我們可以處理主要問題:建構所有具有給定節點數量的高度平衡二元樹。hbal_tree_nodes n 會返回所有具有 n 個節點的高度平衡二元樹的列表。
找出當 n = 15 時存在多少高度平衡樹。
# List.length (hbal_tree_nodes 15);;
- : int = 1553
最少節點數
以下解答直接來自於問題的翻譯。
# let rec min_nodes h =
if h <= 0 then 0
else if h = 1 then 1
else min_nodes (h - 1) + min_nodes (h - 2) + 1;;
val min_nodes : int -> int = <fun>
然而,它不是最有效率的解答。應該使用最後兩個值作為狀態,以避免雙重遞迴。
# let rec min_nodes_loop m0 m1 h =
if h <= 1 then m1
else min_nodes_loop m1 (m1 + m0 + 1) (h - 1)
let min_nodes h =
if h <= 0 then 0 else min_nodes_loop 0 1 h;;
val min_nodes_loop : int -> int -> int -> int = <fun>
val min_nodes : int -> int = <fun>
不難證明 min_nodes h = Fh+2 - 1,其中 (Fn) 是費波那契數列。
最少高度
反轉公式 max_nodes = 2h - 1,可以直接發現 Hₘᵢₙ(n) = ⌈log₂(n+1)⌉,這很容易實作
# let min_height n = int_of_float (ceil (log (float(n + 1)) /. log 2.));;
val min_height : int -> int = <fun>
讓我們證明 Hₘᵢₙ 公式是有效的。首先,如果 h = min_height n,則存在一個高度為 h 且具有 n 個節點的高度平衡樹。因此 2ʰ - 1 = max_nodes h ≥ n,即 h ≥ log₂(n+1)。為了確立 Hₘᵢₙ(n) 的相等性,必須證明,對於任何 n,都存在一個高度為 Hₘᵢₙ(n) 的高度平衡樹。這是由於關係式 Hₘᵢₙ(n) = 1 + Hₘᵢₙ(n/2),其中 n/2 是整數除法。對於 n 為奇數的情況,這很容易證明 — 因此可以建構一個頂部節點以及兩個高度為 Hₘᵢₙ(n) - 1 且具有 n/2 個節點的子樹。對於 n 為偶數的情況,如果先注意到在這種情況下 ⌈log₂(n+2)⌉ = ⌈log₂(n+1)⌉,則相同的證明也成立 — 使用 log₂(n+1) ≤ h ∈ ℕ ⇔ 2ʰ ≥ n + 1 以及 2ʰ 為偶數的事實。這使得可以有一個具有 n/2 個節點的子樹。對於另一個具有 n/2-1 個節點的子樹,必須證明 Hₘᵢₙ(n/2-1) ≥ Hₘᵢₙ(n) - 2,這很容易,因為如果 h = Hₘᵢₙ(n/2-1),則 h+2 ≥ log₂(2n) ≥ log₂(n+1)。
然而,上述函式並不是最好的。實際上,並非每個 64 位元的整數都可以精確地表示為浮點數。以下是一個只使用整數運算的函式
# let rec ceil_log2_loop log plus1 n =
if n = 1 then if plus1 then log + 1 else log
else ceil_log2_loop (log + 1) (plus1 || n land 1 <> 0) (n / 2)
let ceil_log2 n = ceil_log2_loop 0 false n;;
val ceil_log2_loop : int -> bool -> int -> int = <fun>
val ceil_log2 : int -> int = <fun>
然而,這個演算法仍然不是最快的。例如,請參閱Hacker's Delight,第 5-3 節(和 11-4 節)。
遵循與上述相同的想法,如果 h = max_height n,則很容易推斷出 min_nodes h ≤ n < min_nodes(h+1)。這會產生以下程式碼
# let rec max_height_search h n =
if min_nodes h <= n then max_height_search (h + 1) n else h - 1
let max_height n = max_height_search 0 n;;
val max_height_search : int -> int -> int = <fun>
val max_height : int -> int = <fun>
當然,由於 min_nodes 是以遞迴方式計算的,因此不需要重新計算所有內容才能從 min_nodes h 到 min_nodes(h+1)。
# let rec max_height_search h m_h m_h1 n =
if m_h <= n then max_height_search (h + 1) m_h1 (m_h1 + m_h + 1) n else h - 1
let max_height n = max_height_search 0 0 1 n;;
val max_height_search : int -> int -> int -> int -> int = <fun>
val max_height : int -> int = <fun>
建構樹
首先,我們定義一些方便的函式。fold_range 會將函式 f 折疊到範圍 n0...n1,也就是計算 f (... f (f (f init n0) (n0+1)) (n0+2) ...) n1。你可以將其視為執行指派 init ← f init n,其中 n = n0,..., n1,只是程式碼中沒有可變的變數。
# let rec fold_range ~f ~init n0 n1 =
if n0 > n1 then init else fold_range ~f ~init:(f init n0) (n0 + 1) n1;;
val fold_range : f:('a -> int -> 'a) -> init:'a -> int -> int -> 'a = <fun>
在建構樹時,存在一個明顯的對稱性:如果交換平衡樹的左右子樹,我們仍然有一個平衡樹。以下函式會返回 trees 中的所有樹及其排列。
# let rec add_swap_left_right trees =
List.fold_left (fun a n -> match n with
| Node (v, t1, t2) -> Node (v, t2, t1) :: a
| Empty -> a) trees trees;;
val add_swap_left_right : 'a binary_tree list -> 'a binary_tree list = <fun>
最後,我們使用先前計算的界限遞迴地產生所有樹。它可以進一步優化,但我們的目標是直接表達這個想法。
# let rec hbal_tree_nodes_height h n =
assert(min_nodes h <= n && n <= max_nodes h);
if h = 0 then [Empty]
else
let acc = add_hbal_tree_node [] (h - 1) (h - 2) n in
let acc = add_swap_left_right acc in
add_hbal_tree_node acc (h - 1) (h - 1) n
and add_hbal_tree_node l h1 h2 n =
let min_n1 = max (min_nodes h1) (n - 1 - max_nodes h2) in
let max_n1 = min (max_nodes h1) (n - 1 - min_nodes h2) in
fold_range min_n1 max_n1 ~init:l ~f:(fun l n1 ->
let t1 = hbal_tree_nodes_height h1 n1 in
let t2 = hbal_tree_nodes_height h2 (n - 1 - n1) in
List.fold_left (fun l t1 ->
List.fold_left (fun l t2 -> Node ('x', t1, t2) :: l) l t2) l t1
)
let hbal_tree_nodes n =
fold_range (min_height n) (max_height n) ~init:[] ~f:(fun l h ->
List.rev_append (hbal_tree_nodes_height h n) l);;
val hbal_tree_nodes_height : int -> int -> char binary_tree list = <fun>
val add_hbal_tree_node :
char binary_tree list -> int -> int -> int -> char binary_tree list = <fun>
val hbal_tree_nodes : int -> char binary_tree list = <fun>
計算二元樹的葉節點數
葉節點是一個沒有後繼節點的節點。撰寫一個函式 count_leaves 來計算它們。
# count_leaves Empty;;
- : int = 0
# let rec count_leaves = function
| Empty -> 0
| Node (_, Empty, Empty) -> 1
| Node (_, l, r) -> count_leaves l + count_leaves r;;
val count_leaves : 'a binary_tree -> int = <fun>
將二元樹的葉節點收集到列表中
葉節點是一個沒有後繼節點的節點。撰寫一個函式 leaves 來將它們收集到列表中。
# leaves Empty;;
- : 'a list = []
# (* Having an accumulator acc prevents using inefficient List.append.
* Every Leaf will be pushed directly into accumulator.
* Not tail-recursive, but that is no problem since we have a binary tree and
* and stack depth is logarithmic. *)
let leaves t =
let rec leaves_aux t acc = match t with
| Empty -> acc
| Node (x, Empty, Empty) -> x :: acc
| Node (x, l, r) -> leaves_aux l (leaves_aux r acc)
in
leaves_aux t [];;
val leaves : 'a binary_tree -> 'a list = <fun>
將二元樹的內部節點收集到列表中
二元樹的內部節點有一個或兩個非空的後繼節點。撰寫一個函式 internals 來將它們收集到列表中。
# internals (Node ('a', Empty, Empty));;
- : char list = []
# (* Having an accumulator acc prevents using inefficient List.append.
* Every internal node will be pushed directly into accumulator.
* Not tail-recursive, but that is no problem since we have a binary tree and
* and stack depth is logarithmic. *)
let internals t =
let rec internals_aux t acc = match t with
| Empty -> acc
| Node (x, Empty, Empty) -> acc
| Node (x, l, r) -> internals_aux l (x :: internals_aux r acc)
in
internals_aux t [];;
val internals : 'a binary_tree -> 'a list = <fun>
將給定層級的節點收集到列表中
如果從根節點到節點的路徑長度為 N-1,則二元樹的節點位於 N 層。根節點位於第 1 層。撰寫一個函式 at_level t l 來將樹 t 中位於 l 層的所有節點收集到列表中。
# let example_tree =
Node ('a', Node ('b', Node ('d', Empty, Empty), Node ('e', Empty, Empty)),
Node ('c', Empty, Node ('f', Node ('g', Empty, Empty), Empty)));;
val example_tree : char binary_tree =
Node ('a', Node ('b', Node ('d', Empty, Empty), Node ('e', Empty, Empty)),
Node ('c', Empty, Node ('f', Node ('g', Empty, Empty), Empty)))
# at_level example_tree 2;;
- : char list = ['b'; 'c']
使用 at_level,很容易建構一個函式 levelorder,來建立節點的層級順序序列。然而,還有更有效的方法可以做到這一點。
# (* Having an accumulator acc prevents using inefficient List.append.
* Every node at level N will be pushed directly into accumulator.
* Not tail-recursive, but that is no problem since we have a binary tree and
* and stack depth is logarithmic. *)
let at_level t level =
let rec at_level_aux t acc counter = match t with
| Empty -> acc
| Node (x, l, r) ->
if counter=level then
x :: acc
else
at_level_aux l (at_level_aux r acc (counter + 1)) (counter + 1)
in
at_level_aux t [] 1;;
val at_level : 'a binary_tree -> int -> 'a list = <fun>
建構一個完整的二元樹
一個高度為 H 的完整二元樹定義如下:層級 1、2、3、...、H-1 包含最大數量的節點(也就是在 i 層有 2i-1 個節點,請注意我們從根節點的 1 開始計算層級)。在可能包含少於最大可能節點數的 H 層中,所有節點都是「左對齊」的。這表示在層級順序的樹狀遍歷中,所有內部節點都先出現,葉節點排在第二位,而空的後繼節點(也就是實際上不是節點的 nil!)排在最後。
特別是,完整的二元樹被用作堆的資料結構(或定址方案)。
我們可以透過層級順序枚舉節點,從根節點的數字 1 開始,為完整二元樹中的每個節點指派一個位址編號。這樣做時,我們意識到,對於每個位址為 A 的節點 X,都符合以下屬性:X 的左和右後繼節點的位址分別為 2*A 和 2*A+1,假設後繼節點存在。這個事實可以用來優雅地建構完整的二元樹結構。撰寫一個函式 is_complete_binary_tree,其規範如下:is_complete_binary_tree n t 會在 t 是具有 n 個節點的完整二元樹時返回 true。
# complete_binary_tree [1; 2; 3; 4; 5; 6];;
- : int binary_tree =
Node (1, Node (2, Node (4, Empty, Empty), Node (5, Empty, Empty)),
Node (3, Node (6, Empty, Empty), Empty))
# let rec split_n lst acc n = match (n, lst) with
| (0, _) -> (List.rev acc, lst)
| (_, []) -> (List.rev acc, [])
| (_, h :: t) -> split_n t (h :: acc) (n-1)
let rec myflatten p c =
match (p, c) with
| (p, []) -> List.map (fun x -> Node (x, Empty, Empty)) p
| (x :: t, [y]) -> Node (x, y, Empty) :: myflatten t []
| (ph :: pt, x :: y :: t) -> (Node (ph, x, y)) :: myflatten pt t
| _ -> invalid_arg "myflatten"
let complete_binary_tree = function
| [] -> Empty
| lst ->
let rec aux l = function
| [] -> []
| lst -> let p, c = split_n lst [] (1 lsl l) in
myflatten p (aux (l + 1) c)
in
List.hd (aux 0 lst);;
val split_n : 'a list -> 'a list -> int -> 'a list * 'a list = <fun>
val myflatten : 'a list -> 'a binary_tree list -> 'a binary_tree list = <fun>
val complete_binary_tree : 'a list -> 'a binary_tree = <fun>
二元樹的佈局(1)
作為繪製樹的準備工作,需要佈局演算法來決定每個節點在矩形網格中的位置。可以想像幾種佈局方法,其中一種如圖所示。
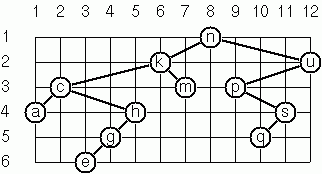
在這個佈局策略中,節點 v 的位置是透過以下兩個規則取得的
- x(v) 等於節點 v 在中序序列中的位置;
- y(v) 等於節點 v 在樹中的深度。
為了儲存節點的位置,我們將在每個節點的值中加入位置 (x,y)。
上面圖示的樹是
# let example_layout_tree =
let leaf x = Node (x, Empty, Empty) in
Node ('n', Node ('k', Node ('c', leaf 'a',
Node ('h', Node ('g', leaf 'e', Empty), Empty)),
leaf 'm'),
Node ('u', Node ('p', Empty, Node ('s', leaf 'q', Empty)), Empty));;
val example_layout_tree : char binary_tree =
Node ('n',
Node ('k',
Node ('c', Node ('a', Empty, Empty),
Node ('h', Node ('g', Node ('e', Empty, Empty), Empty), Empty)),
Node ('m', Empty, Empty)),
Node ('u', Node ('p', Empty, Node ('s', Node ('q', Empty, Empty), Empty)),
Empty))
# layout_binary_tree_1 example_layout_tree;;
- : (char * int * int) binary_tree =
Node (('n', 8, 1),
Node (('k', 6, 2),
Node (('c', 2, 3), Node (('a', 1, 4), Empty, Empty),
Node (('h', 5, 4),
Node (('g', 4, 5), Node (('e', 3, 6), Empty, Empty), Empty), Empty)),
Node (('m', 7, 3), Empty, Empty)),
Node (('u', 12, 2),
Node (('p', 9, 3), Empty,
Node (('s', 11, 4), Node (('q', 10, 5), Empty, Empty), Empty)),
Empty))
# let layout_binary_tree_1 t =
let rec layout depth x_left = function
(* This function returns a pair: the laid out tree and the first
* free x location *)
| Empty -> (Empty, x_left)
| Node (v,l,r) ->
let (l', l_x_max) = layout (depth + 1) x_left l in
let (r', r_x_max) = layout (depth + 1) (l_x_max + 1) r in
(Node ((v, l_x_max, depth), l', r'), r_x_max)
in
fst (layout 1 1 t);;
val layout_binary_tree_1 : 'a binary_tree -> ('a * int * int) binary_tree =
<fun>
二元樹的佈局(2)
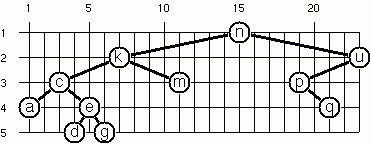
此圖中描述了一種替代的佈局方法。找出規則並撰寫相應的 OCaml 函式。
提示:在給定的層級上,相鄰節點之間的水平距離是恆定的。
顯示的樹是
# let example_layout_tree =
let leaf x = Node (x, Empty, Empty) in
Node ('n', Node ('k', Node ('c', leaf 'a',
Node ('e', leaf 'd', leaf 'g')),
leaf 'm'),
Node ('u', Node ('p', Empty, leaf 'q'), Empty));;
val example_layout_tree : char binary_tree =
Node ('n',
Node ('k',
Node ('c', Node ('a', Empty, Empty),
Node ('e', Node ('d', Empty, Empty), Node ('g', Empty, Empty))),
Node ('m', Empty, Empty)),
Node ('u', Node ('p', Empty, Node ('q', Empty, Empty)), Empty))
# layout_binary_tree_2 example_layout_tree ;;
- : (char * int * int) binary_tree =
Node (('n', 15, 1),
Node (('k', 7, 2),
Node (('c', 3, 3), Node (('a', 1, 4), Empty, Empty),
Node (('e', 5, 4), Node (('d', 4, 5), Empty, Empty),
Node (('g', 6, 5), Empty, Empty))),
Node (('m', 11, 3), Empty, Empty)),
Node (('u', 23, 2),
Node (('p', 19, 3), Empty, Node (('q', 21, 4), Empty, Empty)), Empty))
# let layout_binary_tree_2 t =
let rec height = function
| Empty -> 0
| Node (_, l, r) -> 1 + max (height l) (height r) in
let tree_height = height t in
let rec find_missing_left depth = function
| Empty -> tree_height - depth
| Node (_, l, _) -> find_missing_left (depth + 1) l in
let translate_dst = 1 lsl (find_missing_left 0 t) - 1 in
(* remember than 1 lsl a = 2ᵃ *)
let rec layout depth x_root = function
| Empty -> Empty
| Node (x, l, r) ->
let spacing = 1 lsl (tree_height - depth - 1) in
let l' = layout (depth + 1) (x_root - spacing) l
and r' = layout (depth + 1) (x_root + spacing) r in
Node((x, x_root, depth), l',r') in
layout 1 ((1 lsl (tree_height - 1)) - translate_dst) t;;
val layout_binary_tree_2 : 'a binary_tree -> ('a * int * int) binary_tree =
<fun>
二元樹的佈局(3)
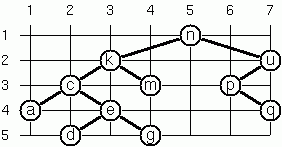
上圖顯示了另一種佈局策略。此方法產生非常緊湊的佈局,同時在每個節點中保持一定的對稱性。找出規則並撰寫相應的述詞。
提示:考慮節點及其後繼節點之間的水平距離。你可以將兩個子樹緊密地包裝在一起,以建構組合的二元樹嗎?這是一個難題。不要太早放棄!
# let example_layout_tree =
let leaf x = Node (x, Empty, Empty) in
Node ('n', Node ('k', Node ('c', leaf 'a',
Node ('h', Node ('g', leaf 'e', Empty), Empty)),
leaf 'm'),
Node ('u', Node ('p', Empty, Node ('s', leaf 'q', Empty)), Empty));;
val example_layout_tree : char binary_tree =
Node ('n',
Node ('k',
Node ('c', Node ('a', Empty, Empty),
Node ('h', Node ('g', Node ('e', Empty, Empty), Empty), Empty)),
Node ('m', Empty, Empty)),
Node ('u', Node ('p', Empty, Node ('s', Node ('q', Empty, Empty), Empty)),
Empty))
# layout_binary_tree_3 example_layout_tree ;;
- : (char * int * int) binary_tree =
Node (('n', 5, 1),
Node (('k', 3, 2),
Node (('c', 2, 3), Node (('a', 1, 4), Empty, Empty),
Node (('h', 3, 4),
Node (('g', 2, 5), Node (('e', 1, 6), Empty, Empty), Empty), Empty)),
Node (('m', 4, 3), Empty, Empty)),
Node (('u', 7, 2),
Node (('p', 6, 3), Empty,
Node (('s', 7, 4), Node (('q', 6, 5), Empty, Empty), Empty)),
Empty))
你最喜歡哪種佈局?
為了緊密地包裝樹,佈局函式除了返回樹的佈局外,還會返回樹的左右輪廓,也就是相對於樹的根節點位置的偏移量列表。
# let layout_binary_tree_3 =
let rec translate_x d = function
| Empty -> Empty
| Node ((v, x, y), l, r) ->
Node ((v, x + d, y), translate_x d l, translate_x d r) in
(* Distance between a left subtree given by its right profile [lr]
and a right subtree given by its left profile [rl]. *)
let rec dist lr rl = match lr, rl with
| lrx :: ltl, rlx :: rtl -> max (lrx - rlx) (dist ltl rtl)
| [], _ | _, [] -> 0 in
let rec merge_profiles p1 p2 = match p1, p2 with
| x1 :: tl1, _ :: tl2 -> x1 :: merge_profiles tl1 tl2
| [], _ -> p2
| _, [] -> p1 in
let rec layout depth = function
| Empty -> ([], Empty, [])
| Node (v, l, r) ->
let (ll, l', lr) = layout (depth + 1) l in
let (rl, r', rr) = layout (depth + 1) r in
let d = 1 + dist lr rl / 2 in
let ll = List.map (fun x -> x - d) ll
and lr = List.map (fun x -> x - d) lr
and rl = List.map ((+) d) rl
and rr = List.map ((+) d) rr in
(0 :: merge_profiles ll rl,
Node((v, 0, depth), translate_x (-d) l', translate_x d r'),
0 :: merge_profiles rr lr) in
fun t -> let (l, t', _) = layout 1 t in
let x_min = List.fold_left min 0 l in
translate_x (1 - x_min) t';;
val layout_binary_tree_3 : 'a binary_tree -> ('a * int * int) binary_tree =
<fun>
二元樹的字串表示法
有人將二元樹表示為以下類型的字串(請參閱範例):"a(b(d,e),c(,f(g,)))"。
- 撰寫一個 OCaml 函式
string_of_tree,如果樹是像平常一樣給定(以Empty或Node(x,l,r)項的形式),則會產生這個字串表示法。然後撰寫一個函式tree_of_string來執行反向操作;也就是說,給定字串表示法,建構通常形式的樹。最後,將兩個述詞組合在一個函式tree_string中,該函式可以在兩個方向上使用。 - 使用差異列表和單一述詞
tree_dlist撰寫相同的述詞tree_string,該述詞會在樹和差異列表之間進行雙向轉換。
為簡化起見,假設節點中的資訊是單個字母,並且字串中沒有空格。
# let example_layout_tree =
let leaf x = Node (x, Empty, Empty) in
(Node ('a', Node ('b', leaf 'd', leaf 'e'),
Node ('c', Empty, Node ('f', leaf 'g', Empty))));;
val example_layout_tree : char binary_tree =
Node ('a', Node ('b', Node ('d', Empty, Empty), Node ('e', Empty, Empty)),
Node ('c', Empty, Node ('f', Node ('g', Empty, Empty), Empty)))
一個簡單的解答是
# let rec string_of_tree = function
| Empty -> ""
| Node(data, l, r) ->
let data = String.make 1 data in
match l, r with
| Empty, Empty -> data
| _, _ -> data ^ "(" ^ (string_of_tree l)
^ "," ^ (string_of_tree r) ^ ")";;
val string_of_tree : char binary_tree -> string = <fun>
也可以使用緩衝區來分配更少的記憶體
# let rec buffer_add_tree buf = function
| Empty -> ()
| Node (data, l, r) ->
Buffer.add_char buf data;
match l, r with
| Empty, Empty -> ()
| _, _ -> Buffer.add_char buf '(';
buffer_add_tree buf l;
Buffer.add_char buf ',';
buffer_add_tree buf r;
Buffer.add_char buf ')'
let string_of_tree t =
let buf = Buffer.create 128 in
buffer_add_tree buf t;
Buffer.contents buf;;
val buffer_add_tree : Buffer.t -> char binary_tree -> unit = <fun>
val string_of_tree : char binary_tree -> string = <fun>
對於反向轉換,我們假設字串格式正確,並且不處理錯誤報告。
# let tree_of_string =
let rec make ofs s =
if ofs >= String.length s || s.[ofs] = ',' || s.[ofs] = ')' then
(Empty, ofs)
else
let v = s.[ofs] in
if ofs + 1 < String.length s && s.[ofs + 1] = '(' then
let l, ofs = make (ofs + 2) s in (* skip "v(" *)
let r, ofs = make (ofs + 1) s in (* skip "," *)
(Node (v, l, r), ofs + 1) (* skip ")" *)
else (Node (v, Empty, Empty), ofs + 1)
in
fun s -> fst (make 0 s);;
val tree_of_string : string -> char binary_tree = <fun>
二元樹的前序和中序序列
我們考慮節點以單個小寫字母識別的二元樹,如先前問題的範例所示。
- 撰寫函式
preorder和inorder,分別建構給定二元樹的前序和中序序列。結果應該是原子(atoms),例如,前一個問題中範例的前序序列應為 'abdecfg'。 - 您可以使用第 1 部分問題中的
preorder反向操作嗎?也就是說,給定一個前序序列,建構對應的樹?如果不行,請進行必要的調整。 - 如果給定二元樹節點的前序序列和中序序列,則該樹會被明確地確定。撰寫一個函式
pre_in_tree來完成此任務。 - 使用差分列表解決問題 1 到 3。太棒了!使用函式
timeit(定義於問題「比較計算歐拉總計函數的兩種方法。」中)來比較這些解決方案。
如果同一個字元出現在多個節點中會發生什麼?例如,嘗試 pre_in_tree "aba" "baa"。
# preorder (Node (1, Node (2, Empty, Empty), Empty));;
- : int list = [1; 2]
我們使用列表來表示結果。請注意,可以透過避免列表串接來提高 preorder 和 inorder 的效率。
# let rec preorder = function
| Empty -> []
| Node (v, l, r) -> v :: (preorder l @ preorder r)
let rec inorder = function
| Empty -> []
| Node (v, l, r) -> inorder l @ (v :: inorder r)
let rec split_pre_in p i x accp acci = match (p, i) with
| [], [] -> (List.rev accp, List.rev acci), ([], [])
| h1 :: t1, h2 :: t2 ->
if x = h2 then
(List.tl (List.rev (h1 :: accp)), t1),
(List.rev (List.tl (h2 :: acci)), t2)
else
split_pre_in t1 t2 x (h1 :: accp) (h2 :: acci)
| _ -> assert false
let rec pre_in_tree p i = match (p, i) with
| [], [] -> Empty
| (h1 :: t1), (h2 :: t2) ->
let (lp, rp), (li, ri) = split_pre_in p i h1 [] [] in
Node (h1, pre_in_tree lp li, pre_in_tree rp ri)
| _ -> invalid_arg "pre_in_tree";;
val preorder : 'a binary_tree -> 'a list = <fun>
val inorder : 'a binary_tree -> 'a list = <fun>
val split_pre_in :
'a list ->
'a list ->
'a -> 'a list -> 'a list -> ('a list * 'a list) * ('a list * 'a list) =
<fun>
val pre_in_tree : 'a list -> 'a list -> 'a binary_tree = <fun>
使用差分列表的解決方案。
(* solution pending *)
二元樹的點字串表示法
我們再次考慮以單個小寫字母識別節點的二元樹,如同問題「二元樹的字串表示法」中的範例。這樣的樹可以使用其節點的前序序列來表示,其中在樹遍歷期間遇到空子樹(nil)時會插入點(.)。例如,問題「二元樹的字串表示法」中顯示的樹表示為 'abd..e..c.fg...'。首先,嘗試建立語法(BNF 或語法圖),然後撰寫一個函式 tree_dotstring,該函式可以雙向轉換。使用差分列表。
(* solution pending *)
從節點字串建構樹
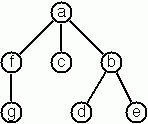
多叉樹由一個根元素和一組(可能為空的)後繼元素組成,後繼元素本身也是多叉樹。多叉樹永遠不為空。後繼樹的集合有時稱為森林。
為了表示多叉樹,我們將使用以下類型,它是定義的直接翻譯
# type 'a mult_tree = T of 'a * 'a mult_tree list;;
type 'a mult_tree = T of 'a * 'a mult_tree list
因此,對面描繪的範例樹由以下 OCaml 表達式表示
# T ('a', [T ('f', [T ('g', [])]); T ('c', []); T ('b', [T ('d', []); T ('e', [])])]);;
- : char mult_tree =
T ('a',
[T ('f', [T ('g', [])]); T ('c', []); T ('b', [T ('d', []); T ('e', [])])])
我們假設多叉樹的節點包含單個字元。在其節點的深度優先順序序列中,每當在樹遍歷期間移動到上一層時,都會插入一個特殊字元 ^。
依照此規則,對面圖中的樹表示為:afg^^c^bd^e^^^。
撰寫函式 string_of_tree : char mult_tree -> string 來建構表示樹的字串,以及 tree_of_string : string -> char mult_tree 來在給定字串時建構樹。
# let t = T ('a', [T ('f', [T ('g', [])]); T ('c', []);
T ('b', [T ('d', []); T ('e', [])])]);;
val t : char mult_tree =
T ('a',
[T ('f', [T ('g', [])]); T ('c', []); T ('b', [T ('d', []); T ('e', [])])])
# (* We could build the final string by string concatenation but
this is expensive due to the number of operations. We use a
buffer instead. *)
let rec add_string_of_tree buf (T (c, sub)) =
Buffer.add_char buf c;
List.iter (add_string_of_tree buf) sub;
Buffer.add_char buf '^'
let string_of_tree t =
let buf = Buffer.create 128 in
add_string_of_tree buf t;
Buffer.contents buf;;
val add_string_of_tree : Buffer.t -> char mult_tree -> unit = <fun>
val string_of_tree : char mult_tree -> string = <fun>
計算多叉樹的節點數
# count_nodes (T ('a', [T ('f', []) ]));;
- : int = 2
# let rec count_nodes (T (_, sub)) =
List.fold_left (fun n t -> n + count_nodes t) 1 sub;;
val count_nodes : 'a mult_tree -> int = <fun>
確定樹的內部路徑長度
我們將多叉樹的內部路徑長度定義為從根到樹的所有節點的路徑長度的總和。根據此定義,先前問題圖中的樹 t 的內部路徑長度為 9。撰寫一個函式 ipl tree,該函式會傳回 tree 的內部路徑長度。
# ipl t;;
- : int = 9
# let rec ipl_sub len (T(_, sub)) =
(* [len] is the distance of the current node to the root. Add the
distance of all sub-nodes. *)
List.fold_left (fun sum t -> sum + ipl_sub (len + 1) t) len sub
let ipl t = ipl_sub 0 t;;
val ipl_sub : int -> 'a mult_tree -> int = <fun>
val ipl : 'a mult_tree -> int = <fun>
建構樹節點的由下而上順序序列
撰寫一個函式 bottom_up t,該函式會建構多叉樹 t 的節點由下而上序列。
# bottom_up (T ('a', [T ('b', [])]));;
- : char list = ['b'; 'a']
# bottom_up t;;
- : char list = ['g'; 'f'; 'c'; 'd'; 'e'; 'b'; 'a']
# let rec prepend_bottom_up (T (c, sub)) l =
List.fold_right (fun t l -> prepend_bottom_up t l) sub (c :: l)
let bottom_up t = prepend_bottom_up t [];;
val prepend_bottom_up : 'a mult_tree -> 'a list -> 'a list = <fun>
val bottom_up : 'a mult_tree -> 'a list = <fun>
類似 Lisp 的樹表示法
在 Lisp 中有一種用於多叉樹的特殊表示法。該圖顯示了如何在 Lisp 中表示多叉樹結構。
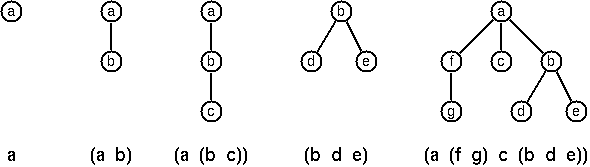
請注意,在「lispy」表示法中,樹中具有後繼節點(子節點)的節點始終是列表中的第一個元素,後接其子節點。多叉樹的「lispy」表示法是一系列原子和括號 '(' 和 ')'。這與 OCaml 中表示樹的方式非常接近,只是沒有使用建構子 T。撰寫一個函式 lispy : char mult_tree -> string,該函式會傳回樹的 lispy 表示法。
# lispy (T ('a', []));;
- : string = "a"
# lispy (T ('a', [T ('b', [])]));;
- : string = "(a b)"
# lispy t;;
- : string = "(a (f g) c (b d e))"
# let rec add_lispy buf = function
| T(c, []) -> Buffer.add_char buf c
| T(c, sub) ->
Buffer.add_char buf '(';
Buffer.add_char buf c;
List.iter (fun t -> Buffer.add_char buf ' '; add_lispy buf t) sub;
Buffer.add_char buf ')'
let lispy t =
let buf = Buffer.create 128 in
add_lispy buf t;
Buffer.contents buf;;
val add_lispy : Buffer.t -> char mult_tree -> unit = <fun>
val lispy : char mult_tree -> string = <fun>
轉換
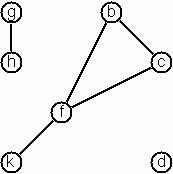
圖定義為一組節點和一組邊,其中每條邊都是一對不同的節點。
在 OCaml 中有多種表示圖的方式。
- 一種方法是列出所有邊,其中邊是一對節點。 以這種形式,上面描述的圖表示為以下表達式
# [('h', 'g'); ('k', 'f'); ('f', 'b'); ('f', 'c'); ('c', 'b')];;
- : (char * char) list =
[('h', 'g'); ('k', 'f'); ('f', 'b'); ('f', 'c'); ('c', 'b')]
我們稱此為邊子句形式。顯然,無法表示孤立的節點。
- 另一種方法是將整個圖表示為一個資料物件。根據圖定義為兩個集合(節點和邊)的一對,我們可以使用以下 OCaml 類型
# type 'a graph_term = {nodes : 'a list; edges : ('a * 'a) list};;
type 'a graph_term = { nodes : 'a list; edges : ('a * 'a) list; }
然後,上面的範例圖表示為
# let example_graph =
{nodes = ['b'; 'c'; 'd'; 'f'; 'g'; 'h'; 'k'];
edges = [('h', 'g'); ('k', 'f'); ('f', 'b'); ('f', 'c'); ('c', 'b')]};;
val example_graph : char graph_term =
{nodes = ['b'; 'c'; 'd'; 'f'; 'g'; 'h'; 'k'];
edges = [('h', 'g'); ('k', 'f'); ('f', 'b'); ('f', 'c'); ('c', 'b')]}
我們稱此為圖項形式。請注意,列表保持排序,它們實際上是集合,沒有重複的元素。每條邊只在邊列表中出現一次;也就是說,從節點 x 到另一個節點 y 的邊表示為 (x, y),不出現 (y, x) 這一對。圖項形式是我們的預設表示法。 您可能需要使用集合而不是列表來定義類似的類型。
- 第三種表示方法是將每個節點與相鄰的節點集合關聯。我們稱此為鄰接列表形式。在我們的範例中
let adjacency_example = ['b', ['c'; 'f'];
'c', ['b'; 'f'];
'd', [];
'f', ['b'; 'c'; 'k'];
'g', ['h'];
'k', ['f']
];;
val adjacency_example : (char * char list) list =
[('b', ['c'; 'f']); ('c', ['b'; 'f']); ('d', []); ('f', ['b'; 'c'; 'k']);
('g', ['h']); ('k', ['f'])]
- 到目前為止,我們介紹的表示法非常適合自動處理,但它們的語法不是很使用者友善。手動輸入術語既繁瑣又容易出錯。我們可以定義更緊湊且「人性化」的表示法,如下所示:以原子和 X-Y 類型的項表示圖(使用字元標記節點)。原子代表孤立的節點,X-Y 項描述邊。如果 X 作為邊的端點出現,則會自動定義為節點。我們的範例可以寫成
# "b-c f-c g-h d f-b k-f h-g";;
- : string = "b-c f-c g-h d f-b k-f h-g"
我們稱此為人性化形式。如範例所示,列表不必排序,甚至可能多次包含相同的邊。請注意孤立的節點 d。
撰寫函式以在不同的圖表示法之間進行轉換。使用這些函式,所有表示法都是等效的;也就是說,對於以下問題,您可以隨意選擇最方便的形式。這個問題不是特別困難,但是處理所有特殊情況需要做很多工作。
(* example pending *)
從一個節點到另一個節點的路徑
撰寫一個函式 paths g a b,該函式會傳回圖 g 中從節點 a 到節點 b ≠ a 的所有無環路徑 p。該函式應透過回溯傳回所有路徑的列表。
# let example_graph =
{nodes = ['b'; 'c'; 'd'; 'f'; 'g'; 'h'; 'k'];
edges = [('h', 'g'); ('k', 'f'); ('f', 'b'); ('f', 'c'); ('c', 'b')]};;
val example_graph : char graph_term =
{nodes = ['b'; 'c'; 'd'; 'f'; 'g'; 'h'; 'k'];
edges = [('h', 'g'); ('k', 'f'); ('f', 'b'); ('f', 'c'); ('c', 'b')]}
# paths example_graph 'f' 'b';;
- : char list list = [['f'; 'c'; 'b']; ['f'; 'b']]
# (* The datastructures used here are far from the most efficient ones
but allow for a straightforward implementation. *)
(* Returns all neighbors satisfying the condition. *)
let neighbors g a cond =
let edge l (b, c) = if b = a && cond c then c :: l
else if c = a && cond b then b :: l
else l in
List.fold_left edge [] g.edges
let rec list_path g a to_b = match to_b with
| [] -> assert false (* [to_b] contains the path to [b]. *)
| a' :: _ ->
if a' = a then [to_b]
else
let n = neighbors g a' (fun c -> not (List.mem c to_b)) in
List.concat_map (fun c -> list_path g a (c :: to_b)) n
let paths g a b =
assert(a <> b);
list_path g a [b];;
val neighbors : 'a graph_term -> 'a -> ('a -> bool) -> 'a list = <fun>
val list_path : 'a graph_term -> 'a -> 'a list -> 'a list list = <fun>
val paths : 'a graph_term -> 'a -> 'a -> 'a list list = <fun>
從給定節點開始的環路
撰寫一個函式 cycle g a,該函式會傳回圖 g 中從給定節點 a 開始的閉合路徑(環路)p。此述詞應透過回溯傳回所有環路的列表。
# let example_graph =
{nodes = ['b'; 'c'; 'd'; 'f'; 'g'; 'h'; 'k'];
edges = [('h', 'g'); ('k', 'f'); ('f', 'b'); ('f', 'c'); ('c', 'b')]};;
val example_graph : char graph_term =
{nodes = ['b'; 'c'; 'd'; 'f'; 'g'; 'h'; 'k'];
edges = [('h', 'g'); ('k', 'f'); ('f', 'b'); ('f', 'c'); ('c', 'b')]}
# cycles example_graph 'f';;
- : char list list =
[['f'; 'b'; 'c'; 'f']; ['f'; 'c'; 'f']; ['f'; 'c'; 'b'; 'f'];
['f'; 'b'; 'f']; ['f'; 'k'; 'f']]
# let cycles g a =
let n = neighbors g a (fun _ -> true) in
let p = List.concat_map (fun c -> list_path g a [c]) n in
List.map (fun p -> p @ [a]) p;;
val cycles : 'a graph_term -> 'a -> 'a list list = <fun>
建構所有生成樹
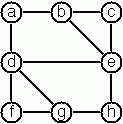
撰寫一個函式 s_tree g 來建構(透過回溯)給定圖 g 的所有生成樹。使用此述詞,找出左側所示圖有多少個生成樹。此範例圖的資料可在下面的測試中找到。當您有 s_tree 函式的正確解決方案時,請使用它來定義另外兩個有用的函式:is_tree graph 和 is_connected Graph。這兩者都是五分鐘的任務!
# let g = {nodes = ['a'; 'b'; 'c'; 'd'; 'e'; 'f'; 'g'; 'h'];
edges = [('a', 'b'); ('a', 'd'); ('b', 'c'); ('b', 'e');
('c', 'e'); ('d', 'e'); ('d', 'f'); ('d', 'g');
('e', 'h'); ('f', 'g'); ('g', 'h')]};;
val g : char graph_term =
{nodes = ['a'; 'b'; 'c'; 'd'; 'e'; 'f'; 'g'; 'h'];
edges =
[('a', 'b'); ('a', 'd'); ('b', 'c'); ('b', 'e'); ('c', 'e'); ('d', 'e');
('d', 'f'); ('d', 'g'); ('e', 'h'); ('f', 'g'); ('g', 'h')]}
(* solution pending *);;
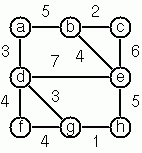
建構最小生成樹
撰寫一個函式 ms_tree graph 來建構給定標記圖的最小生成樹。標記圖將表示如下
# type ('a, 'b) labeled_graph = {nodes : 'a list;
labeled_edges : ('a * 'a * 'b) list};;
type ('a, 'b) labeled_graph = {
nodes : 'a list;
labeled_edges : ('a * 'a * 'b) list;
}
(請注意,從現在開始,nodes 和 edges 會遮蓋同名的先前欄位。)
提示: 使用Prim 演算法。對 P83 的解決方案進行少量修改即可完成此任務。右側範例圖的資料可在下方找到。
# let g = {nodes = ['a'; 'b'; 'c'; 'd'; 'e'; 'f'; 'g'; 'h'];
labeled_edges = [('a', 'b', 5); ('a', 'd', 3); ('b', 'c', 2);
('b', 'e', 4); ('c', 'e', 6); ('d', 'e', 7);
('d', 'f', 4); ('d', 'g', 3); ('e', 'h', 5);
('f', 'g', 4); ('g', 'h', 1)]};;
val g : (char, int) labeled_graph =
{nodes = ['a'; 'b'; 'c'; 'd'; 'e'; 'f'; 'g'; 'h'];
labeled_edges =
[('a', 'b', 5); ('a', 'd', 3); ('b', 'c', 2); ('b', 'e', 4);
('c', 'e', 6); ('d', 'e', 7); ('d', 'f', 4); ('d', 'g', 3);
('e', 'h', 5); ('f', 'g', 4); ('g', 'h', 1)]}
(* solution pending *);;
圖同構
如果存在一個雙射 f: N1 → N2,使得對於 N1 的任何節點 X 和 Y,當且僅當 f(X) 和 f(Y) 相鄰時,X 和 Y 相鄰,則兩個圖 G1(N1,E1) 和 G2(N2,E2) 是同構的。
撰寫一個函式來判斷兩個圖是否同構。
提示: 使用開放式列表來表示函式 f。
# let g = {nodes = [1; 2; 3; 4; 5; 6; 7; 8];
edges = [(1, 5); (1, 6); (1, 7); (2, 5); (2, 6); (2, 8); (3, 5);
(3, 7); (3, 8); (4, 6); (4, 7); (4, 8)]};;
val g : int graph_term =
{nodes = [1; 2; 3; 4; 5; 6; 7; 8];
edges =
[(1, 5); (1, 6); (1, 7); (2, 5); (2, 6); (2, 8); (3, 5); (3, 7);
(3, 8); (4, 6); (4, 7); (4, 8)]}
(* solution pending *);;
節點度數和圖著色
- 撰寫一個函式
degree graph node,該函式會判斷給定節點的度數。 - 撰寫一個函式,該函式會產生圖的所有節點列表,並根據度數遞減排序。
- 使用Welsh-Powell 演算法來繪製圖的節點,使相鄰節點具有不同的顏色。
(* example pending *);;
深度優先順序圖遍歷
撰寫一個函式,該函式會產生深度優先順序圖遍歷序列。應指定起點,並且輸出應是可從該起點到達的節點列表(按深度優先順序)。
具體來說,將會透過其鄰接列表表示法提供圖,您必須建立具有以下簽名的模組 M
# module type GRAPH = sig
type node = char
type t
val of_adjacency : (node * node list) list -> t
val dfs_fold : t -> node -> ('a -> node -> 'a) -> 'a -> 'a
end;;
module type GRAPH =
sig
type node = char
type t
val of_adjacency : (node * node list) list -> t
val dfs_fold : t -> node -> ('a -> node -> 'a) -> 'a -> 'a
end
其中 M.dfs_fold g n f a 會以深度優先順序將 f 套用在圖 g 的節點上,從節點 n 開始。
# let g = M.of_adjacency
['u', ['v'; 'x'];
'v', ['y'];
'w', ['z'; 'y'];
'x', ['v'];
'y', ['x'];
'z', ['z'];
];;
val g : M.t = <abstr>
在深度優先搜尋中,您會先完整探索最近探索的節點 *v* 的邊,然後「回溯」以探索離開探索 *v* 的節點的邊。進行深度優先搜尋表示要仔細追蹤哪些頂點已被造訪以及何時被造訪。
我們會計算搜尋中探索的每個頂點的時間戳記。已探索的頂點有兩個與之關聯的時間戳記:其探索時間(在對應 d 中)和完成時間(在對應 f 中)(當完全檢查完頂點的鄰接列表時,頂點即完成)。這些時間戳記在圖演算法中通常很有用,並有助於推斷深度優先搜尋的行為。
我們會在搜尋期間為節點著色,以協助進行記錄(對應 color)。圖的所有頂點最初都是 White。當探索到頂點時,會將其標記為 Gray,而當完成時,會將其標記為 Black。
如果在先前探索的節點 *u* 的鄰接列表中探索到頂點 *v*,則此事實會記錄在先行子圖(對應 pred)中。
# module M : GRAPH = struct
module Char_map = Map.Make (Char)
type node = char
type t = (node list) Char_map.t
let of_adjacency l =
List.fold_right (fun (x, y) -> Char_map.add x y) l Char_map.empty
type colors = White|Gray|Black
type 'a state = {
d : int Char_map.t; (*discovery time*)
f : int Char_map.t; (*finishing time*)
pred : char Char_map.t; (*predecessor*)
color : colors Char_map.t; (*vertex colors*)
acc : 'a; (*user specified type used by 'fold'*)
}
let dfs_fold g c fn acc =
let rec dfs_visit t u {d; f; pred; color; acc} =
let edge (t, state) v =
if Char_map.find v state.color = White then
dfs_visit t v {state with pred = Char_map.add v u state.pred}
else (t, state)
in
let t, {d; f; pred; color; acc} =
let t = t + 1 in
List.fold_left edge
(t, {d = Char_map.add u t d; f;
pred; color = Char_map.add u Gray color; acc = fn acc u})
(Char_map.find u g)
in
let t = t + 1 in
t , {d; f = Char_map.add u t f; pred;
color = Char_map.add u Black color; acc}
in
let v = List.fold_left (fun k (x, _) -> x :: k) []
(Char_map.bindings g) in
let initial_state=
{d = Char_map.empty;
f = Char_map.empty;
pred = Char_map.empty;
color = List.fold_right (fun x -> Char_map.add x White)
v Char_map.empty;
acc}
in
(snd (dfs_visit 0 c initial_state)).acc
end;;
module M : GRAPH
使用 N 個節點產生 K-規則簡單圖
(* example pending *);;
八皇后問題
這是一個計算機科學中的經典問題。目標是在西洋棋盤上放置八個皇后,使她們彼此之間不會互相攻擊;也就是說,沒有兩個皇后在同一行、同一列或同一對角線上。
提示: 將皇后的位置表示為數字 1..N 的列表。範例:[4; 2; 7; 3; 6; 8; 5; 1] 表示第一列的皇后在第 4 行,第二列的皇后在第 2 行,依此類推。使用生成與測試範例。
# queens_positions 4;;
- : int list list = [[3; 1; 4; 2]; [2; 4; 1; 3]]
這是一個枚舉所有可能解的暴力演算法。如需更深入的分析,請參考維基百科。
# let possible row col used_rows usedD1 usedD2 =
not (List.mem row used_rows
|| List.mem (row + col) usedD1
|| List.mem (row - col) usedD2)
let queens_positions n =
let rec aux row col used_rows usedD1 usedD2 =
if col > n then [List.rev used_rows]
else
(if row < n then aux (row + 1) col used_rows usedD1 usedD2
else [])
@ (if possible row col used_rows usedD1 usedD2 then
aux 1 (col + 1) (row :: used_rows) (row + col :: usedD1)
(row - col :: usedD2)
else [])
in aux 1 1 [] [] [];;
val possible : int -> int -> int list -> int list -> int list -> bool = <fun>
val queens_positions : int -> int list list = <fun>
騎士巡邏
另一個著名的問題是:騎士如何在 N×N 的棋盤上跳躍,使其恰好訪問每個方格一次?
提示: 使用座標對 (x,y) 表示方格,其中 x 和 y 都是介於 1 和 N 之間的整數。定義函式 jump n (x,y),該函式返回騎士在 n×n 棋盤上從 (x,y) 可以跳到的所有座標 (u,v)。最後,將我們問題的解表示為騎士位置的列表(騎士巡邏)。
(* example pending *);;
馮·科赫猜想
幾年前,我遇到一位數學家,他對一個他不知道解決方案的問題感到好奇。他的名字叫馮·科赫,我不知道這個問題是否已經解決。
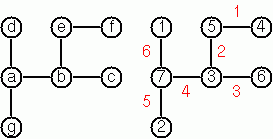
無論如何,這個謎題是這樣的:給定一個具有 N 個節點(因此有 N-1 條邊)的樹。找到一種方法將節點從 1 到 N 編號,並相應地將邊從 1 到 N-1 編號,使得對於每個邊 K,其節點編號的差等於 K。猜想是這總是可能的。
對於小樹,這個問題很容易用手解決。但是,對於較大的樹,14 已經很大了,很難找到解決方案。請記住,我們不確定是否總是存在解決方案!
編寫一個函式,計算給定樹的編號方案。這裡顯示的較大樹的解決方案是什麼?
(* example pending *);;
算術謎題
給定一個整數列表,找到一種插入算術符號(運算符)的正確方法,使得結果是一個正確的方程式。範例:使用數字列表 [2; 3; 5; 7; 11],我們可以形成方程式 2 - 3 + 5 + 7 = 11 或 2 = (3 * 5 + 7) / 11(以及其他十個!)。
(* example pending *);;
英文數字詞
在財務文件(如支票)上,數字有時必須用完整的單詞書寫。範例:175 必須寫成 one-seven-five。編寫函式 full_words 以完整單詞列印(非負)整數。
# full_words 175;;
- : string = "one-seven-five"
# let full_words =
let digit = [|"zero"; "one"; "two"; "three"; "four"; "five"; "six";
"seven"; "eight"; "nine"|] in
let rec words w n =
if n = 0 then (match w with [] -> [digit.(0)] | _ -> w)
else words (digit.(n mod 10) :: w) (n / 10)
in
fun n -> String.concat "-" (words [] n);;
val full_words : int -> string = <fun>
語法檢查器
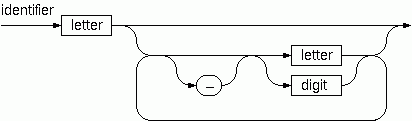
在某種程式語言(Ada)中,識別符號由對面的語法圖(鐵路圖)定義。將語法圖轉換為不包含迴圈的語法圖系統;也就是說,純粹是遞迴的。使用這些修改後的圖,編寫一個函式 identifier : string -> bool,它可以檢查給定的字串是否為合法的識別符號。
# identifier "this-is-a-long-identifier";;
- : bool = true
# let identifier =
let is_letter c = 'a' <= c && c <= 'z' in
let is_letter_or_digit c = is_letter c || ('0' <= c && c <= '9') in
let rec is_valid s i not_after_dash =
if i < 0 then not_after_dash
else if is_letter_or_digit s.[i] then is_valid s (i - 1) true
else if s.[i] = '-' && not_after_dash then is_valid s (i - 1) false
else false in
fun s -> (
let n = String.length s in
n > 0 && is_letter s.[n - 1] && is_valid s (n - 2) true);;
val identifier : string -> bool = <fun>
數獨
數獨謎題是這樣的
Problem statement Solution
. . 4 | 8 . . | . 1 7 9 3 4 | 8 2 5 | 6 1 7
| | | |
6 7 . | 9 . . | . . . 6 7 2 | 9 1 4 | 8 5 3
| | | |
5 . 8 | . 3 . | . . 4 5 1 8 | 6 3 7 | 9 2 4
--------+---------+-------- --------+---------+--------
3 . . | 7 4 . | 1 . . 3 2 5 | 7 4 8 | 1 6 9
| | | |
. 6 9 | . . . | 7 8 . 4 6 9 | 1 5 3 | 7 8 2
| | | |
. . 1 | . 6 9 | . . 5 7 8 1 | 2 6 9 | 4 3 5
--------+---------+-------- --------+---------+--------
1 . . | . 8 . | 3 . 6 1 9 7 | 5 8 2 | 3 4 6
| | | |
. . . | . . 6 | . 9 1 8 5 3 | 4 7 6 | 2 9 1
| | | |
2 4 . | . . 1 | 5 . . 2 4 6 | 3 9 1 | 5 7 8
謎題中的每個位置都屬於一個(水平)行和一個(垂直)列,以及一個單獨的 3x3 方格(我們簡稱其為「方格」)。一開始,某些位置帶有 1 到 9 之間的個位數數字。問題是將遺失的位置填入數字,使得 1 到 9 之間的每個數字在每一行、每一列和每個方格中恰好出現一次。
# (* The board representation is not imposed. Here "0" stands for "." *);;
解決這個問題的一個簡單方法是使用暴力破解。這個想法是開始在每種情況下填入可用的值,並測試它是否有效。當沒有可用的值時,表示我們犯了一個錯誤,因此我們回到我們做出的最後一個選擇,並嘗試不同的選擇。
# open Printf
module Board = struct
type t = int array (* 9×9, row-major representation. A value of 0
means undecided. *)
let is_valid c = c >= 1
let get (b : t) (x, y) = b.(x + y * 9)
let get_as_string (b : t) pos =
let i = get b pos in
if is_valid i then string_of_int i else "."
let with_val (b : t) (x, y) v =
let b = Array.copy b in
b.(x + y * 9) <- v;
b
let of_list l : t =
let b = Array.make 81 0 in
List.iteri (fun y r -> List.iteri (fun x e ->
b.(x + y * 9) <- if e >= 0 && e <= 9 then e else 0) r) l;
b
let print b =
for y = 0 to 8 do
for x = 0 to 8 do
printf (if x = 0 then "%s" else if x mod 3 = 0 then " | %s"
else " %s") (get_as_string b (x, y))
done;
if y < 8 then
if y mod 3 = 2 then printf "\n--------+---------+--------\n"
else printf "\n | | \n"
else printf "\n"
done
let available b (x, y) =
let avail = Array.make 10 true in
for i = 0 to 8 do
avail.(get b (x, i)) <- false;
avail.(get b (i, y)) <- false;
done;
let sq_x = x - x mod 3 and sq_y = y - y mod 3 in
for x = sq_x to sq_x + 2 do
for y = sq_y to sq_y + 2 do
avail.(get b (x, y)) <- false;
done;
done;
let av = ref [] in
for i = 1 (* not 0 *) to 9 do if avail.(i) then av := i :: !av done;
!av
let next (x,y) = if x < 8 then (x + 1, y) else (0, y + 1)
(** Try to fill the undecided entries. *)
let rec fill b ((x, y) as pos) =
if y > 8 then Some b (* filled all entries *)
else if is_valid(get b pos) then fill b (next pos)
else match available b pos with
| [] -> None (* no solution *)
| l -> try_values b pos l
and try_values b pos = function
| v :: l ->
(match fill (with_val b pos v) (next pos) with
| Some _ as res -> res
| None -> try_values b pos l)
| [] -> None
end
let sudoku b = match Board.fill b (0, 0) with
| Some b -> b
| None -> failwith "sudoku: no solution";;
module Board :
sig
type t = int array
val is_valid : int -> bool
val get : t -> int * int -> int
val get_as_string : t -> int * int -> string
val with_val : t -> int * int -> int -> int array
val of_list : int list list -> t
val print : t -> unit
val available : t -> int * int -> int list
val next : int * int -> int * int
val fill : t -> int * int -> t option
val try_values : t -> int * int -> int list -> t option
end
val sudoku : Board.t -> Board.t = <fun>
繪圖方塊
大約在 1994 年,一種謎題在英國非常流行。「星期日電訊報」寫道:「繪圖方塊是來自日本的謎題,目前每週僅在星期日電訊報上刊登。只需運用您的邏輯和技能來完成網格,並揭示圖片或圖表。」身為 OCaml 程式設計師,您的處境更好:您可以讓您的電腦完成這項工作!
這個謎題是這樣的:基本上,矩形點陣圖的每一行和每一列都標註了其不同的已佔用單元字串的各自長度。解決謎題的人必須僅根據這些長度完成點陣圖。
Problem statement: Solution:
|_|_|_|_|_|_|_|_| 3 |_|X|X|X|_|_|_|_| 3
|_|_|_|_|_|_|_|_| 2 1 |X|X|_|X|_|_|_|_| 2 1
|_|_|_|_|_|_|_|_| 3 2 |_|X|X|X|_|_|X|X| 3 2
|_|_|_|_|_|_|_|_| 2 2 |_|_|X|X|_|_|X|X| 2 2
|_|_|_|_|_|_|_|_| 6 |_|_|X|X|X|X|X|X| 6
|_|_|_|_|_|_|_|_| 1 5 |X|_|X|X|X|X|X|_| 1 5
|_|_|_|_|_|_|_|_| 6 |X|X|X|X|X|X|_|_| 6
|_|_|_|_|_|_|_|_| 1 |_|_|_|_|X|_|_|_| 1
|_|_|_|_|_|_|_|_| 2 |_|_|_|X|X|_|_|_| 2
1 3 1 7 5 3 4 3 1 3 1 7 5 3 4 3
2 1 5 1 2 1 5 1
對於上面的範例,該問題可以表示為兩個列表 [[3]; [2; 1]; [3; 2]; [2; 2]; [6]; [1; 5]; [6]; [1]; [2]] 和 [[1; 2]; [3; 1]; [1; 5]; [7; 1]; [5]; [3]; [4]; [3]],它們分別給出了從上到下和從左到右的行和列的「實心」長度。已發佈的謎題比這個範例更大,例如 25×20,並且顯然總是有唯一的解。
# solve [[3]; [2; 1]; [3; 2]; [2; 2]; [6]; [1; 5]; [6]; [1]; [2]]
[[1; 2]; [3; 1]; [1; 5]; [7; 1]; [5]; [3]; [4]; [3]];;
暴力解法:構造棋盤,嘗試所有給定列的模式的填充可能性,如果它不滿足行模式,則拒絕該解。
# type element = Empty | X (* ensure we do not miss cases in patterns *);;
type element = Empty | X
您可能想查看更有效率的演算法並實作它們,以便您可以在合理的時間內解決以下問題
solve [[14]; [1; 1]; [7; 1]; [3; 3]; [2; 3; 2];
[2; 3; 2]; [1; 3; 6; 1; 1]; [1; 8; 2; 1]; [1; 4; 6; 1]; [1; 3; 2; 5; 1; 1];
[1; 5; 1]; [2; 2]; [2; 1; 1; 1; 2]; [6; 5; 3]; [12]]
[[7]; [2; 2]; [2; 2]; [2; 1; 1; 1; 1]; [1; 2; 4; 2];
[1; 1; 4; 2]; [1; 1; 2; 3]; [1; 1; 3; 2]; [1; 1; 1; 2; 2; 1]; [1; 1; 5; 1; 2];
[1; 1; 7; 2]; [1; 6; 3]; [1; 1; 3; 2]; [1; 4; 3]; [1; 3; 1];
[1; 2; 2]; [2; 1; 1; 1; 1]; [2; 2]; [2; 2]; [7]]
填字遊戲
給定一個空的(或幾乎空的)填字遊戲框架和一組單詞。問題是將單詞放入框架中。
特定的填字遊戲在文字檔中指定,該文字檔首先以任意順序列出單詞(每行一個單詞)。然後,在空行之後,定義填字遊戲框架。在此框架規格中,空字元位置以點 (.) 表示。為了使解決方案更容易,字元位置也可以包含預定義的字元值。上面的謎題在檔案 p7_09a.dat 中定義,其他範例是 p7_09b.dat 和 p7_09d.dat。還有一個沒有解決方案的謎題範例(p7_09c.dat)。
單詞是至少包含兩個字元的字串(字元列表)。填字遊戲框架中字元位置的水平或垂直序列稱為位置。我們的問題是找到一種將單詞放置到位置上的相容方法。
提示
- 這個問題不容易。您需要一些時間才能徹底理解它。所以,不要太早放棄!請記住,目標是乾淨的解決方案,而不僅僅是快速且骯髒的駭客攻擊!
- 出於效率原因,至少對於較大的謎題,以特定順序排序單詞和位置非常重要。
(* example pending *);;
永無止境的序列
列表是有限的,這意味著它們總是包含有限數量的元素。序列可以是有限的或無限的。
本練習的目標是定義一個只包含無限序列的類型 'a stream。使用此類型,定義以下函式
val hd : 'a stream -> 'a
(** Returns the first element of a stream *)
val tl : 'a stream -> 'a stream
(** Removes the first element of a stream *)
val take : int -> 'a stream -> 'a list
(** [take n seq] returns the n first values of [seq] *)
val unfold : ('a -> 'b * 'a) -> 'a -> 'b stream
(** Similar to Seq.unfold *)
val bang : 'a -> 'a stream
(** [bang x] produces an infinitely repeating sequence of [x] values. *)
val ints : int -> int stream
(* Similar to Seq.ints *)
val map : ('a -> 'b) -> 'a stream -> 'b stream
(** Similar to List.map and Seq.map *)
val filter: ('a -> bool) -> 'a stream -> 'a stream
(** Similar to List.filter and Seq.filter *)
val iter : ('a -> unit) -> 'a stream -> 'b
(** Similar to List.iter and Seq.iter *)
val to_seq : 'a stream -> 'a Seq.t
(** Translates an ['a stream] into an ['a Seq.t] *)
val of_seq : 'a Seq.t -> 'a stream
(** Translates an ['a Seq.t] into an ['a stream]
@raise Failure if the input sequence is finite. *)
提示: 使用 let ... = 模式。
type 'a cons = Cons of 'a * 'a stream
and 'a stream = unit -> 'a cons
let hd (seq : 'a stream) = let (Cons (x, _)) = seq () in x
let tl (seq : 'a stream) = let (Cons (_, seq)) = seq () in seq
let rec take n seq = if n = 0 then [] else let (Cons (x, seq)) = seq () in x :: take (n - 1) seq
let rec unfold f x () = let (y, x) = f x in Cons (y, unfold f x)
let bang x = unfold (fun x -> (x, x)) x
let ints x = unfold (fun x -> (x, x + 1)) x
let rec map f seq () = let (Cons (x, seq)) = seq () in Cons (f x, map f seq)
let rec filter p seq () = let (Cons (x, seq)) = seq () in let seq = filter p seq in if p x then Cons (x, seq) else seq ()
let rec iter f seq = let (Cons (x, seq)) = seq () in f x; iter f seq
let to_seq seq = Seq.unfold (fun seq -> Some (hd seq, tl seq)) seq
let rec of_seq seq () = match seq () with
| Seq.Nil -> failwith "Not a infinite sequence"
| Seq.Cons (x, seq) -> Cons (x, of_seq seq)
序列序列的對角線
編寫一個函式 diag : 'a Seq.t Seq.t -> 'a Seq,它返回序列序列的對角線。返回的序列形成如下:返回序列的第一個元素是第一個序列的第一個元素;返回序列的第二個元素是第二個序列的第二個元素;返回序列的第三個元素是第三個序列的第三個元素;依此類推。
let rec diag seq_seq () =
let hds, tls = Seq.filter_map Seq.uncons seq_seq |> Seq.split in
let hd, tl = Seq.uncons hds |> Option.map fst, Seq.uncons tls |> Option.map snd in
let d = Option.fold ~none:Seq.empty ~some:diag tl in
Option.fold ~none:Fun.id ~some:Seq.cons hd d ()