效能分析
速度
為什麼 OCaml 很快?事實上,退一步問 OCaml 真的快嗎? 我們如何讓程式更快?在本章中,我們將探討當你將 OCaml 程式編譯成機器碼時實際會發生什麼。這將有助於了解為什麼 OCaml 不僅是一個很棒的程式語言,而且實際上也是一種非常快速的語言。它也會幫助你幫助編譯器為你編寫更好的機器碼。我認為(無論如何)程式設計師應該對你輸入 ocamlopt 和得到一個可以執行的二進制檔案之間發生的事情有所了解。
但你需要了解一些組合語言才能充分利用本節。不要害怕!我會透過將組合語言翻譯成類似 C 的偽代碼來幫助你(畢竟 C 只是一種可移植的組合語言)。
組合語言基礎
本章中的範例都是在 x86 Linux 機器上編譯的。x86 當然是 32 位元的機器,所以 x86 的一個「字」是 4 個位元組(= 32 位元)長。在這個層次上,OCaml 主要處理字大小的物件,因此你需要記住乘以四才能得到位元組大小。
為了喚起你的記憶,x86 只有少數通用暫存器,每個暫存器都可以儲存一個字。Linux 組譯器在暫存器名稱前面加上 %。暫存器為:%eax、%ebx、%ecx、%edx、%esi、%edi、%ebp(用於堆疊框架的特殊暫存器)和 %esp(堆疊指標)。
Linux 組譯器(與其他 Unix 組譯器相同,但與 MS 衍生組譯器相反)將暫存器/記憶體的移動寫成
movl from, to
因此 movl %ebx, %eax 的意思是「將暫存器 %ebx 的內容複製到暫存器 %eax」(而不是反過來)。
我們將要看的大部分組合語言並不是由像 movl 這樣的機器碼指令主導,而是由所謂的組譯器指示詞主導。這些指示詞以 .(句點)開頭,它們實際上是指示組譯器做某事。以下是 Linux 組譯器的常見指示詞
.text
Text 是 Unix 用來表示「程式碼」的方式。text 區段簡單來說就是可執行檔中儲存程式碼的部分。.text 指示詞會切換組譯器,使其開始寫入 text 區段。
.data
類似地,.data 指示詞會切換組譯器,使其開始寫入可執行檔的 data 區段(部分)。
.globl foo
foo:
這會宣告一個名為 foo 的全域符號。這表示下一個要來的東西的位址可以命名為 foo。如果只寫 foo: 而沒有前面的 .globl 指示詞,則會宣告一個局部符號(僅限於目前檔案)。
.long 12345
.byte 9
.ascii "hello"
.space 4
.long 會將一個字(4 個位元組)寫入目前的區段。.byte 會寫入單一位元組。.ascii 會寫入一個位元組字串(非以 null 結尾)。.space 會寫入指定數量的零位元組。通常你在資料區段中使用這些。
「hello, world」程式
將以下程式放入名為 smallest.ml 的檔案中
print_string "hello, world\n"
並使用以下指令將其編譯為原生碼可執行檔
ocamlopt -S smallest.ml -o smallest
-S(大寫 S)會告訴編譯器保留組合語言檔案(名為 smallest.s - 小寫 s),而不是將其刪除。
以下是 smallest.s 檔案的重點編輯,並加入了我的註解。首先是資料區段
.data
.long 4348 ; header for string
.globl Smallest__1
lest__1:
.ascii "hello, world\12" ; string
.space 2 ; padding ..
.byte 2 ; .. after string
接下來是 text(程式碼)區段
.text
.globl Smallest__entry ; entry point to the program
lest__entry:
; this is equivalent to the C pseudo-code:
; Pervasives.output_string (stdout, &Smallest__1)
movl $Smallest__1, %ebx
movl Pervasives + 92, %eax ; Pervasives + 92 == stdout
call Pervasives__output_string_212
; return 1
movl $1, %eax
ret
在 C 語言中,所有東西都必須在函式內部。想想你不能直接在 C 語言中寫 printf ("hello, world\n");,而必須將其放在 main () { ... } 內。在 OCaml 中,你可以在頂層使用命令,而不是在函式內部。但是當我們將其翻譯成組合語言時,我們應該將這些命令放在哪裡?必須有一些方法可以從外部呼叫這些命令,因此它們需要以某種方式標記。從程式碼片段中你可以看到,OCaml 透過取得檔案名稱 (smallest.ml),將其大寫並加上 __entry 來解決這個問題,從而建立一個名為 Smallest__entry 的符號來指代此檔案中的頂層命令。
現在看看 OCaml 產生的程式碼。原始程式碼說 print_string "hello, world\n",但 OCaml 卻編譯了相當於 Pervasives.output_string stdout "hello, world\n" 的程式碼。為什麼?如果你查看 pervasives.ml,你就會知道原因
let print_string s = output_string stdout s
OCaml 已經內聯這個函式。內聯 - 取得一個函式並從其定義展開它 - 有時是一種效能優勢,因為它可以避免額外函式呼叫的開銷,並且可以為最佳化器創造更多機會來執行其操作。有時內聯並不好,因為它會導致程式碼膨脹,從而破壞處理器快取所做的良好工作(而且,函式呼叫在現代處理器上實際上根本不貴)。OCaml 會內聯像這樣的簡單呼叫,因為它們基本上是無風險的,幾乎總是會帶來小幅的效能提升。
我們還能注意到什麼?呼叫慣例似乎是前兩個參數分別傳遞到 %eax 和 %ebx 暫存器中。其他參數可能在堆疊上傳遞,但我們稍後會看到。
C 程式有一個簡單的字串儲存慣例,稱為 ASCIIZ。這僅表示字串以 ASCII 格式儲存,後跟一個尾隨的 NUL (\0) 字元。OCaml 以不同的方式儲存字串,我們可以從上面的資料區段中看到。此字串的儲存方式如下
4 byte header: 4348
the string: h e l l o , SP w o r l d \n
padding: \0 \0 \002
首先,填充使字串的總長度達到整數個字(在此範例中為 4 個字,16 個位元組)。填充經過精心設計,因此你可以計算出字串的實際位元組長度,前提是你知道配置給字串的字總數。此編碼是明確的(你可以自行驗證)。
具有明確長度的字串的一個優點是,你可以在其中表示包含 ASCII NUL (\0) 字元的字串,這在 C 中很難做到。但是,另一方面,如果你將 OCaml 字串傳遞給某些 C 原生程式碼,則需要注意這一點:如果它包含 ASCII NUL,則 C str* 函式將會失敗。
其次,我們有標頭。OCaml 中每個封裝(配置)的物件都有一個標頭,它會告訴垃圾回收器物件的大小(以字為單位),以及物件所包含的內容。將數字 4348 寫成二進位
length of the object in words: 0000 0000 0000 0000 0001 00 (4 words)
color (used by GC): 00
tag: 1111 1100 (String_tag)
有關 OCaml 中堆積配置物件的格式的詳細資訊,請參閱 /usr/include/caml/mlvalues.h。
一個不尋常的地方是,程式碼會將指向字串開頭的指標(即標頭後面的第一個字)傳遞給 Pervasives.output_string。這表示 output_string 必須從指標減去 4 才能取得標頭,以判斷字串的長度。
在這個簡單的例子中,我遺漏了什麼?嗯,上面的文字片段並非完整的故事。如果 OCaml 能將那個簡單的 hello world 程式翻譯成上面顯示的五行組合語言,那就太好了。但是,實際程式中是誰呼叫 Smallest__entry 呢?為此,OCaml 包含了一大堆引導程式碼,這些程式碼會執行諸如啟動垃圾收集器、分配和初始化記憶體、呼叫函式庫中的初始化器等操作。OCaml 會將所有這些程式碼靜態連結到最終的可執行檔,這就是為什麼我最終得到的程式(在 Linux 上)會有 95,442 位元組的原因。儘管如此,程式的啟動時間仍然非常短(不到一毫秒),相較之下,啟動一個合理的 Java 程式需要幾秒鐘,而啟動一個 Perl 腳本則需要一秒左右。
尾遞迴
我們在第 6 章提到,OCaml 可以將尾遞迴函式呼叫轉換為簡單的迴圈。這是真的嗎?讓我們看看簡單的尾遞迴會編譯成什麼樣子
let rec loop () =
print_string "I go on forever ...";
loop ()
let () = loop ()
該檔案名為 tail.ml,因此根據 OCaml 命名函式的慣例,我們的函式將被稱為 Tail__loop_nnn(其中 nnn 是 OCaml 附加的一些唯一數字,用於區分名稱相同的函式)。
以下是上面定義的 loop 函式的組合語言
.text
.globl Tail__loop_56
Tail__loop_56:
.L100:
; Print the string
movl $Tail__2, %ebx
movl Pervasives + 92, %eax
call Pervasives__output_string_212
.L101:
; The following movl is in fact obsolete:
movl $1, %eax
; Jump back to the .L100 label above (ie. loop forever)
jmp .L100
結論很明顯。呼叫 Tail__loop_56 會先印出字串,然後跳回頂部,然後印出字串,然後跳回,如此反覆執行。這是一個簡單的迴圈,不是遞迴函式呼叫,因此它不會使用任何堆疊空間。
題外話:型別在哪裡?
正如我們之前多次說過的那樣,OCaml 是靜態型別的,因此在編譯時,OCaml 知道 loop 的型別是 unit -> unit。它知道 "hello, world\n" 的型別是 string。它沒有嘗試將這個事實傳達給 output_string 函式。output_string 預期接收一個 channel 和一個 string 作為參數,事實上它也確實收到了這些參數。如果我們傳遞一個 int 而不是 string,會發生什麼事?
這基本上是不可能的狀況。因為 OCaml 在編譯時知道型別,所以它不需要在執行時處理型別或檢查型別。在純 OCaml 中,沒有任何方法可以「欺騙」編譯器產生對 Pervasives.output_string stdout 1 的呼叫。這樣的錯誤會在編譯時由型別推斷標記出來,因此永遠無法編譯。
結果是,當我們將 OCaml 程式碼編譯成組合語言時,大多數情況下不需要型別資訊,尤其是在我們上面看過的案例中,型別在編譯時完全已知,並且沒有發生多型。
在編譯時完全了解所有型別是一項重大的效能提升,因為它可以完全避免在執行時進行任何動態型別檢查。例如,將其與 Java 方法調用進行比較:obj.method ()。這是一個昂貴的操作,因為您需要找到 obj 所屬的具體類別,然後查找該方法,而且您可能需要每次呼叫任何方法時都執行所有這些操作。在 Java 中,轉換物件是另一個需要在執行時執行大量工作的情況。OCaml 的靜態型別不允許任何這些操作。
多型型別
您可能從上面的討論中猜到,多型(即編譯器在編譯時沒有完全知道函式的型別)可能會對效能產生影響。假設我們需要一個函式來計算兩個整數的最大值。我們的第一次嘗試是
# let max a b =
if a > b then a else b;;
val max : 'a -> 'a -> 'a = <fun>
夠簡單了,但請回想一下,OCaml 中的 >(大於)運算符是多型的。它的型別是 'a -> 'a -> bool,這表示我們上面定義的 max 函式將是多型的
# let max a b =
if a > b then a else b;;
val max : 'a -> 'a -> 'a = <fun>
這確實反映在 OCaml 為此函式產生的程式碼中,該程式碼相當複雜
.text
.globl Max__max_56
Max__max_56:
; Reserve two words of stack space.
subl $8, %esp
; Save the first and second arguments (a and b) on the stack.
movl %eax, 4(%esp)
movl %ebx, 0(%esp)
; Call the C "greaterthan" function (in the OCaml library).
pushl %ebx
pushl %eax
movl $greaterthan, %eax
call caml_c_call
.L102:
addl $8, %esp
; If the C "greaterthan" function returned 1, jump to .L100
cmpl $1, %eax
je .L100
; Returned 0, so get argument a which we previously saved on
; the stack and return it.
movl 4(%esp), %eax
addl $8, %esp
ret
; Returned 1, so get argument b which we previously saved on
; the stack and return it.
.L100:
movl 0(%esp), %eax
addl $8, %esp
ret
基本上,> 運算透過呼叫 OCaml 函式庫中的 C 函式來完成。這顯然效率不高,遠不及如果我們可以產生一些快速內聯組合語言來執行 > 時的效率。
這並非完全沒有意義。我們只需要提示 OCaml 編譯器,參數實際上是整數。然後 OCaml 將產生一個 max 的專用版本,該版本僅適用於 int 參數
# let max (a : int) (b : int) =
if a > b then a else b;;
val max : int -> int -> int = <fun>
以下是為此函式產生的組合語言程式碼
.text
.globl Max_int__max_56
Max_int__max_56:
; Single assembly instruction "cmpl" for performing the > op.
cmpl %ebx, %eax
; If %ebx > %eax, jump to .L100
jle .L100
; Just return argument a.
ret
; Return argument b.
.L100:
movl %ebx, %eax
ret
只有 5 行組合語言,而且盡可能簡單。
這個程式碼呢
# let max a b =
if a > b then a else b;;
val max : 'a -> 'a -> 'a = <fun>
# let () = print_int (max 2 3);;
3
OCaml 是否聰明到足以內聯 max 函式並將其專門用於整數?令人失望的是,答案是否定的。OCaml 仍然必須產生外部 Max.max 符號(因為這是一個模組,所以該函式可能會從模組外部呼叫),並且它不會內聯該函式。
這是另一個變體
# let max a b =
if a > b then a else b in
print_int (max 2 3);;
3
- : unit = ()
令人失望的是,儘管此程式碼中的 max 定義是本地的(無法從模組外部呼叫),但 OCaml 仍然不會專門化該函式。
教訓:如果您有一個無意中成為多型的函式,那麼您可以透過指定一個或多個參數的型別來幫助編譯器。
整數、標籤位元、堆積配置值的表示
OCaml 中的整數有一些特殊之處。其中之一是整數是 31 位元的實體,而不是 32 位元的實體。「缺失」的位元發生了什麼事?
將其寫入 int.ml
print_int 3
並使用 ocamlopt -S int.ml -o int 編譯,以在 int.s 中產生組合語言。回想一下上面的討論,我們預期 OCaml 會將 print_int 函式內聯為 output_string (string_of_int 3),並且檢查組合語言輸出,我們可以發現這正是 OCaml 所做的
.text
.globl Int__entry
Int__entry:
; Call Pervasives.string_of_int (3)
movl $7, %eax
call Pervasives__string_of_int_152
; Call Pervasives.output_string (stdout, result_of_previous)
movl %eax, %ebx
movl Pervasives + 92, %eax
call Pervasives__output_string_212
重要的程式碼是 movl $7, %eax。它顯示了兩件事:首先,整數是未裝箱的(未在堆積上分配),而是直接在暫存器 %eax 中傳遞給函式。這很快。但是其次,我們看到傳遞的數字是 7,而不是 3。
這是 OCaml 中整數表示的結果。整數的最低位元用作標籤 - 我們接下來將看到它的用途。最高的 31 位元是實際的整數。7 的二進制表示是 111,因此最低標籤位元是 1,而最高的 31 位元形成二進制的數字 11 = 3。要從 OCaml 表示轉換為整數,請除以 2 並向下捨入。
為什麼需要標籤位元?此位元用於區分整數和堆積上結構的指標,只有在我們呼叫多型函式時才需要區分。在上面的情況下,當我們呼叫 string_of_int 時,參數只能是 int,因此永遠不會查詢標籤位元。儘管如此,為了避免對整數使用兩種內部表示,OCaml 中的所有整數都會帶有標籤位元。
要了解為什麼標籤位元確實必要,以及它為什麼在那裡,需要一些關於指標的背景知識。
在 Sparc、MIPS 和 Alpha 等 RISC 晶片的世界中,指標必須以字組對齊。例如,在較舊的 32 位元 Sparc 上,不可能建立和使用未對齊到 4(位元組)的倍數的指標。嘗試使用一個會產生處理器例外,這基本上表示您的程式會發生區段錯誤。這樣做的原因只是為了簡化記憶體存取。如果您只需要擔心字組對齊的存取,那麼設計 CPU 的記憶體子系統會簡單得多。
由於歷史原因(因為 x86 源自 8 位元晶片),x86 一直支援未對齊的記憶體存取,儘管如果您將所有記憶體存取對齊到 4 的倍數,速度會更快。
儘管如此,OCaml 中的所有指標都是對齊的 - 即,對於 32 位元處理器而言是 4 的倍數,對於 64 位元處理器而言是 8 的倍數。這表示 OCaml 中任何指標的最低位元始終為零。
因此,您可以看到,透過查看暫存器的最低位元,您可以立即判斷它是否儲存指標(「標籤」位元為零),或整數(標籤位元設定為一)。
還記得我們在上一節中造成我們許多麻煩的多型 > 函式嗎?我們查看了組合語言,發現每當 OCaml 看到 > 的多型形式時,它都會編譯對名為 greaterthan 的 C 函式的呼叫。此函式採用兩個參數,分別位於暫存器 %eax 和 %ebx 中。但是 greaterthan 可以使用整數、浮點數、字串、不透明物件呼叫...它如何知道 %eax 和 %ebx 指向什麼?
它使用以下決策樹
- 標籤位元為一:比較兩個整數並傳回。
- 標籤位元為零:
%eax和%ebx必須指向兩個堆積配置的記憶體區塊。查看記憶體區塊的標頭字,特別是標頭字的最低 8 位元,這些位元會標記區塊的內容。- String_tag:比較兩個字串。
- Double_tag:比較兩個浮點數。
- 等等。
請注意,因為 > 的型別是 'a -> 'a -> bool,所以兩個參數必須具有相同的型別。編譯器應該在編譯時強制執行此操作。我認為 greaterthan 可能包含在執行時進行健全性檢查的程式碼。
浮點數
預設情況下,浮點數是裝箱的(在堆積上分配)。將此儲存為 float.ml 並使用 ocamlopt -S float.ml -o float 編譯
print_float 3.0
該數字不會像上面的整數一樣,直接在 %eax 暫存器中傳遞給 string_of_float。相反,它會在資料區段中靜態建立
.data
.long 2301
.globl Float__1
Float__1:
.double 3.0
並在 %eax 中傳遞指向浮點數的指標
movl $Float__1, %eax
call Pervasives__string_of_float_157
請注意浮點數的結構:它有一個標頭 (2301),後面跟著數字本身的 8 位元組(2 個字)表示。可以透過將其寫為二進制來解碼標頭
Length of the object in words: 0000 0000 0000 0000 0000 10 (8 bytes)
Color: 00
Tag: 1111 1101 (Double_tag)
string_of_float 不是多型的,但假設我們有一個多型函數 foo : 'a -> unit 接受一個多型參數。如果我們用 %eax 包含 7 來呼叫 foo,這等同於 foo 3,而如果我們用 %eax 包含指向上面 Float__1 的指標來呼叫 foo,這等同於 foo 3.0。
陣列
我之前提到,OCaml 的目標之一是數值計算。數值計算大量使用向量和矩陣,它們本質上是浮點數的陣列。為了加速這個過程,OCaml 實作了未裝箱浮點數的陣列。這表示在我們有一個 float array (浮點數陣列) 型別的物件的特殊情況下,OCaml 會以與 C 相同的方式儲存它們
double array[10];
... 而不是擁有一個指向堆積上十個獨立配置的浮點數的指標陣列。
讓我們實際看看
let a = Array.create 10 0.0;;
for i = 0 to 9 do
a.(i) <- float_of_int i
done
我將使用 -unsafe 選項編譯這段程式碼,以移除邊界檢查 (簡化程式碼以進行此處的說明)。建立陣列的第一行程式碼會編譯成一個簡單的 C 呼叫
pushl $Arrayfloats__1 ; Boxed float 0.0
pushl $21 ; The integer 10
movl $make_vect, %eax ; Address of the C function to call
call caml_c_call
; ...
movl %eax, Arrayfloats ; Store the resulting pointer to the
; array at this place on the heap.
迴圈會編譯成這個相對簡單的組合語言
movl $1, %eax ; Let %eax = 0. %eax is going to store i.
cmpl $19, %eax ; If %eax > 9, then jump out of the
jg .L100 ; loop (to label .L100 at the end).
.L101: ; This is the start of the loop body.
movl Arrayfloats, %ecx ; Address of the array to %ecx.
movl %eax, %ebx ; Copy i to %ebx.
sarl $1, %ebx ; Remove the tag bit from %ebx by
; shifting it right 1 place. So %ebx
; now contains the real integer i.
pushl %ebx ; Convert %ebx to a float.
fildl (%esp)
addl $4, %esp
fstpl -4(%ecx, %eax, 4) ; Store the float in the array at the ith
; position.
addl $2, %eax ; i := i + 1
cmpl $19, %eax ; If i <= 9, loop around again.
jle .L101
.L100:
重要的陳述式是將浮點數儲存到陣列中的那個。它是
fstpl -4(%ecx, %eax, 4)
組合語言的語法相當複雜,但括號中的運算式 -4(%ecx, %eax, 4) 的意思是「在位址 %ecx + 4*%eax - 4」。回想一下,%eax 是 i 的 OCaml 表示法,帶有標籤位元,因此它基本上等於 i*2+1,所以讓我們替換它並乘開
%ecx + 4*%eax - 4
= %ecx + 4*(i*2+1) - 4
= %ecx + 4*i*2 + 4 - 4
= %ecx + 8*i
(陣列中的每個浮點數長 8 個位元組。)
因此,浮點數陣列如預期般是未裝箱的。
部分應用的函數和閉包
OCaml 如何編譯只部分應用的函數?讓我們編譯這段程式碼
Array.map ((+) 2) [|1; 2; 3; 4; 5|]
如果你還記得語法,[| ... |] 宣告一個陣列 (在此情況下為 int array),而 ((+) 2) 是一個閉包 - 「將 2 加到某個東西的函數」。
編譯這段程式碼會揭示一些有趣的新功能。首先是配置陣列的程式碼
movl $24, %eax ; Allocate 5 * 4 + 4 = 24 bytes of memory.
call caml_alloc
leal 4(%eax), %eax ; Let %eax point to 4 bytes into the
; allocated memory.
所有堆積配置都具有相同的格式:4 位元組標頭 + 資料。在這種情況下,資料是 5 個整數,因此我們為標頭配置 4 個位元組,為資料配置 5 * 4 個位元組。我們更新指標以指向第一個資料字,即配置記憶體區塊中的 4 個位元組。
接下來,OCaml 會產生程式碼來初始化陣列
movl $5120, -4(%eax)
movl $3, (%eax)
movl $5, 4(%eax)
movl $7, 8(%eax)
movl $9, 12(%eax)
movl $11, 16(%eax)
標頭字是 5120,如果你以二進位寫入,表示包含 5 個字的區塊,標籤為零。標籤為零表示它是「結構化區塊」,又名陣列。我們也將數字 1、2、3、4 和 5 複製到陣列中的適當位置。請注意,使用了整數的 OCaml 表示法。因為這是一個結構化區塊,垃圾收集器將掃描此區塊中的每個字,而 GC 需要能夠區分整數和指向其他堆積配置區塊的指標 (GC 無法存取有關此陣列的型別資訊)。
接下來,會建立閉包 ((+) 2)。閉包由資料區段中配置的這個區塊表示
.data
.long 3319
.globl Closure__1
Closure__1:
.long caml_curry2
.long 5
.long Closure__fun_58
標頭是 3319,表示長度為 3 個字的 Closure_tag。區塊中的 3 個字是函數 caml_curry2 的位址、整數數字 2 和此函數的位址
.text
.globl Closure__fun_58
Closure__fun_58:
; The function takes two arguments, %eax and %ebx.
; This line causes the function to return %eax + %ebx - 1.
lea -1(%eax, %ebx), %eax
ret
這個函數是做什麼的?表面上,它將兩個參數相加,然後減一。但請記住,%eax 和 %ebx 是整數的 OCaml 表示法。讓我們將它們表示為
%eax = 2 * a + 1%ebx = 2 * b + 1
其中 a 和 b 是實際的整數引數。因此,此函數會傳回
%eax + %ebx - 1
= 2 * a + 1 + 2 * b + 1 - 1
= 2 * a + 2 * b + 1
= 2 * (a + b) + 1
換句話說,此函數會傳回總和 a + b 的 OCaml 整數表示法。此函數是 (+)!
(實際上比這更微妙 - 為了快速執行數學運算,OCaml 以 x86 的位址硬體可能不是 x86 設計者預期的方式使用 x86 位址硬體。)
回到我們的閉包 - 我們不會深入探討 caml_curry2 函數的詳細資訊,但只要說這個閉包是應用於函數 (+) 的引數 2,等待第二個引數。正如預期的那樣。
實際呼叫 Array.map 函數相當難以理解,但我們檢查 OCaml 的重點是程式碼
- 確實會使用明確的閉包呼叫
Array.map。 - 不會嘗試內聯呼叫並將其轉換為迴圈。
以這種方式呼叫 Array.map 無疑比手動撰寫迴圈來遍歷陣列要慢。開銷主要在於必須針對陣列的每個元素評估閉包,這不如將閉包內聯為函數快 (如果這種最佳化甚至可能的話)。但是,如果你有一個比 ((+) 2) 更實質的閉包,開銷會減少。FP 版本也節省了昂貴的程式設計師時間,而不是撰寫命令式迴圈。
效能分析工具
你可以在 OCaml 程式上執行兩種效能分析
- 取得位元組碼的執行計數。
- 取得原生程式碼的真實效能分析。
ocamlcp 和 ocamlprof 程式會在位元組碼上執行效能分析。以下是一個範例
let rec iterate r x_init i =
if i = 1 then x_init
else
let x = iterate r x_init (i - 1) in
r *. x *. (1.0 -. x)
let () =
Random.self_init ();
Graphics.open_graph " 640x480";
for x = 0 to 640 do
let r = 4.0 *. float_of_int x /. 640.0 in
for i = 0 to 39 do
let x_init = Random.float 1.0 in
let x_final = iterate r x_init 500 in
let y = int_of_float (x_final *. 480.) in
Graphics.plot x y
done
done;
Gc.print_stat stdout
可以使用以下方式執行和編譯
$ ocamlcp -p a graphics.cma graphtest.ml -o graphtest
$ ./graphtest
$ ocamlprof graphtest.ml
註解 (* nnn *) 由 ocamlprof 新增,顯示程式碼的每個部分被呼叫了多少次。
原生程式碼的效能分析是使用你的作業系統對效能分析的原生支援完成的。在 Linux 的情況下,我們使用 gprof。另一種選擇是 perf,如下所述。
我們使用 ocamlopt 的 -p 選項進行編譯,這會告知編譯器為 gprof 包含效能分析資訊
在正常執行程式後,效能分析程式碼會傾印出一個檔案 gmon.out,我們可以使用 gprof 解讀它
$ gprof ./a.out
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
10.86 0.57 0.57 2109 0.00 0.00 sweep_slice
9.71 1.08 0.51 1113 0.00 0.00 mark_slice
7.24 1.46 0.38 4569034 0.00 0.00 Sieve__code_begin
6.86 1.82 0.36 9171515 0.00 0.00 Stream__set_data_140
6.57 2.17 0.34 12741964 0.00 0.00 fl_merge_block
6.29 2.50 0.33 4575034 0.00 0.00 Stream__peek_154
5.81 2.80 0.30 12561656 0.00 0.00 alloc_shr
5.71 3.10 0.30 3222 0.00 0.00 oldify_mopup
4.57 3.34 0.24 12561656 0.00 0.00 allocate_block
4.57 3.58 0.24 9171515 0.00 0.00 modify
4.38 3.81 0.23 8387342 0.00 0.00 oldify_one
3.81 4.01 0.20 12561658 0.00 0.00 fl_allocate
3.81 4.21 0.20 4569034 0.00 0.00 Sieve__filter_56
3.62 4.40 0.19 6444 0.00 0.00 empty_minor_heap
3.24 4.57 0.17 3222 0.00 0.00 oldify_local_roots
2.29 4.69 0.12 4599482 0.00 0.00 Stream__slazy_221
2.10 4.80 0.11 4597215 0.00 0.00 darken
1.90 4.90 0.10 4596481 0.00 0.00 Stream__fun_345
1.52 4.98 0.08 4575034 0.00 0.00 Stream__icons_207
1.52 5.06 0.08 4575034 0.00 0.00 Stream__junk_165
1.14 5.12 0.06 1112 0.00 0.00 do_local_roots
[ etc. ]
在 Linux 上使用 perf
假設已安裝 perf 並且你的程式已使用 -g 編譯為原生程式碼 (或 ocamlbuild 標籤 debug),你只需要輸入
perf record --call-graph=dwarf -- ./foo.native a b c d
perf report
第一個命令會以引數 a b c d 啟動 foo.native,並將效能分析資訊記錄在 perf.data 中;第二個命令會啟動一個互動式程式,以探索呼叫圖。選項 --call-graph=dwarf 使 perf 能夠感知 OCaml 的呼叫慣例 (使用舊版本的 perf,在 OCaml 中啟用框架指標可能會有所幫助;opam 提供合適的編譯器開關,例如 4.02.1+fp)。
在 macOS 上使用 Instruments
macOS 隨附一個名為 Instruments 的效能監控和偵錯應用程式,其中包含 CPU 計數器、時間分析器和系統追蹤範本。
啟動它並選取所需的範本後,你必須在啟動應用程式之前開始錄製。
當你啟動應用程式時,即時結果會顯示在 Instrument 的瀏覽器中。
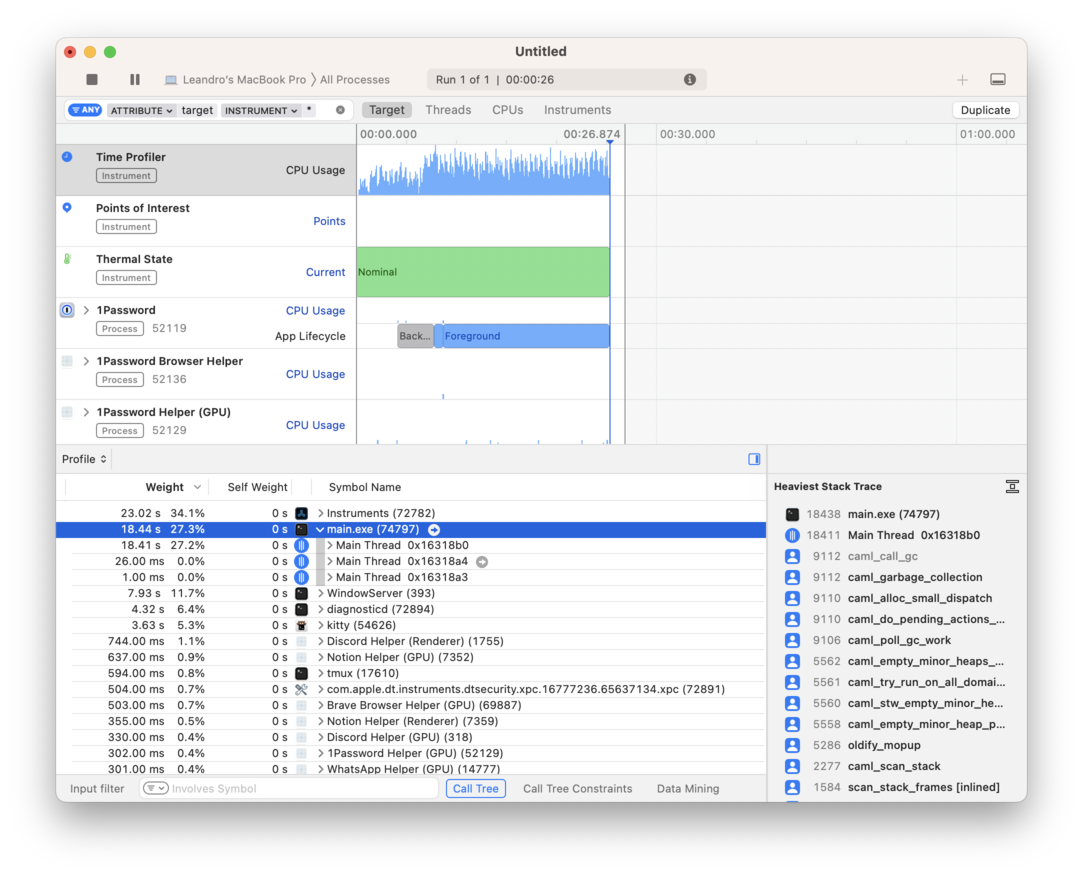
從那裡,你可以點擊你的程式,並深入查看哪些函數執行時間最長。
摘要
總而言之,以下是一些讓你的程式獲得最佳效能的提示
- 盡可能簡單地撰寫程式。如果執行時間太長,請分析它以找出它在哪裡花費時間,並將最佳化集中在這些區域。
- 檢查是否有非預期的多型,並為編譯器新增型別提示。
- 閉包比簡單的函數呼叫慢,但可以提高可維護性和可讀性。
- 作為最後的手段,請使用 C 重新撰寫程式中的熱點 (但首先請檢查 OCaml 編譯器產生的組合語言,看看你是否可以做得比它更好)。
- 效能可能取決於外部因素 (你的資料庫查詢速度?網路速度?)。如果這樣,那麼任何最佳化都無法幫助你。
延伸閱讀
你可以閱讀 OCaml 手冊中的「(使用 C 與 OCaml 介面)」章節,以及查看 mlvalues.h 標頭檔,以了解更多關於 OCaml 如何表示不同型別的資訊。